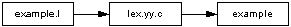
Flex jest generatorem analizatorów leksykalnych.
Działanie flex-a jest przedstawione na rysunku:
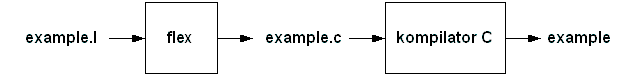
| Wyrażenie | Obejmuje | Przykład |
|---|---|---|
| c | dowolny znak nie będący operatorem | a |
| \c | zwykłe znaczenia znaku | \* |
| "s" | ciąg znaków | "**" |
| . | dowolny znak z wyjątkiem znaku nowej linii | a.b |
| ^ | początej linii | ^początek |
| $ | koniec linii | koniec$ |
| [s] | dowolny znak ze zbioru | [0123abc] |
| [^s] | dowolny znak nie będący w zbiorze | [^0123abc] |
| [s1-s2] | dowolny znak ze zbioru s1-s2 | [0-9] |
| r* | zero badź więcej wystąpień wyrażenia r | a* |
| r+ | jedno badź więcej wystąpień wyrażenia r | a+ |
| r? | zero bądź jedno wystąpienie wyrażenia r | a? |
| r{n,m} | od n do m wystąpień wyrażenia r | a{1,5} |
| r{m} | dokładnie m wystąpień wyrażenia r | a{5} |
| r1r2 | wyrażenie r1 a następnie r2 | ab |
| r1|r2 | wyrażenie r1 lub r2 | a|b |
| (r) | wyrażenie r | (a|b) |
| r1/r2 | wyrażenie r1 gdy następuje po nim r2 | a/b |
| <x> r | wyrażenie r pod warunkiem przebywania w stanie x | <x>abc |
Przykłady:
| Wyrażenie regularne | Akceptowane ciągi znaków |
|---|---|
| flex | flex |
| [0-9][^0-9] | 2a, 3%, 5m |
| L(R[0-9]|L[0-9]) | LR1, LL0 |
| "-"?1 | -1, 1 |
| 0x[0-9A-F]+ | 0xFF |
| DD" "[0-9]{7} | DD 3452378 |
Specyfikacja dla programu flex (plik z rozszerzeniem .l) ma następujący układ:
definicje pomocnicze %% reguły %% podprogramy pomocnicze
Sekcja definicje pomocnicze umożliwiaja zdefinowanie pomocniczych nazw dla złożonych wyrażeń regularnych oraz podanie kodu, który będzie bezpośrdnio kopiowany na początek kodu skanera.
Sekcja reguły zawiera wyrażenia regularnym wraz z przypisanymi im akcjami w języku C (lub C++).
Sekcja podprogramy pomocnicze umożliwia podanie kodu, który ma być skopiowany bezpośrednio na koniec pliku skanera.
Poniżej przedstawiony jest specyfikacja flexa dla skanera, który wyszukuje ciąg znaków lex i zamienia go na ciąg znaków flex.
%{
/* Program wyszukuje ciag znakow "lex" i zamienia go na ciag znakow "flex" */
%}
%%
lex printf("flex");
%%
main() {
printf("Zamiana lex na flex:\n");
yylex();
return 0;
}
Źródła: zamien.l
Inny przykład - skaner dla pseudo-Pascala (źródło: http://www.gnu.org/software/flex/manual/html_mono/flex.html).
/* scanner for a toy Pascal-like language */
%{
/* need this for the call to atof() below */
#include <math.h>
%}
DIGIT [0-9]
ID [a-z][a-z0-9]*
%%
{DIGIT}+ {
printf( "An integer: %s (%d)\n", yytext,
atoi( yytext ) );
}
{DIGIT}+"."{DIGIT}* {
printf( "A float: %s (%g)\n", yytext,
atof( yytext ) );
}
if|then|begin|end|procedure|function {
printf( "A keyword: %s\n", yytext );
}
{ID} printf( "An identifier: %s\n", yytext );
"+"|"-"|"*"|"/" printf( "An operator: %s\n", yytext );
"{"[^}\n]*"}" /* eat up one-line comments */
[ \t\n]+ /* eat up whitespace */
. printf( "Unrecognized character: %s\n", yytext );
%%
main( argc, argv )
int argc;
char **argv;
{
++argv, --argc; /* skip over program name */
if ( argc > 0 )
yyin = fopen( argv[0], "r" );
else
yyin = stdin;
yylex();
}
Źródła: pseudo-pascal.l
Gdy więcej niż jedna reguła pasuje do ciągu wejściowego flex stosuje kolejno dwie zasady:
%%
begin printf("%s slowo kluczowe\n", yytext); // regula 1
[a-z]+ printf("%s identyfikator\n", yytext); // regula 2
.|\n /* empty */
Jeżeli na wejściu pojawi się ciąg znaków beginner, to zadziała reguła 2 i flex potraktuje ciąg znaków jako identyfikator, bo reguła begin dopasuje 5 znaków, a reguła [a-z]+ dopasuje 8 znaków.
Jeżeli na wejściu pojawi się ciąg znaków begin, to zadziała reguła 1 i flex potraktuje go jako słowo kluczowe, bo obie reguły dopasowują po 5 znaków.
Źródła: begin.l
Aby wygenerować kod skanera wpisujemy:
flex zamien.l
Otrzymany w ten sposób kod należy skompilować:
gcc lex.yy.c -o zamien -lfl
Skaner można uruchomić z przykladowym plikiem testowym test_zamien:
./zamien <test_zamien
make jest narzędziem, które pozwala na zautomatyzowanie procesu tworzenia plików wykonywalnych na programów zawierający wiele plików Ľródłowych. Program make odczytuje konfiguracje z pliku o nazwie Makefile. Plik Makefile jest podzielony na sekcje. Każda sekcja ma następującą strukturę:
plik_docelowy: lista_wymaganych_plikow <TAB> polecenie_1 <TAB> polecenie_n
Rozważmy przykład. Mamy stworzyć działający skaner na podstawie specyfikacji flex-a. Zależności pomiędzy plikami ilustruje rysunek.
Przykładowy plik Makefile może wyglądać następująco:
example: lex.yy.c gcc -o example lex.yy.c -lfl lex.yy.c: example.l flex example.l
Źródła: Makefile1
Po wpisaniu make z linii komand polecenia wyspecyfikowane w pliku Makefile zostaną wykonane i zostanie utworzony plik wykonywalny. Poniżej przedstawiony jest przykład wykorzystujacy makra:
PROG = example
all : ${PROG}
lex.yy.c: ${PROG}.l
flex ${PROG}.l
${PROG}: lex.yy.c
gcc -o ${PROG} lex.yy.c -lfl
Źródła: Makefile2
Makra są używane do zastępowania wielokrotnie powtarzających się ciągów znaków. Definicje mark pojawiają się na początku pliku Makefile w postaci: nazwa_makra = zastepowany_ciag_znakow. Odwołania do makr w dalszej częsci pliku Makefile mają postać: ${nazwa_makra}.
Więcej informacji: http://www.mtsu.edu/~csdept/FacilitiesAndResources/make.htm, http://developers.sun.com/solaris/articles/make_utility.html
Generator skanerów flex - manual po polsku.
Flex, version 2.5 - A fast scanner generator, Vern Paxson
Lex - A Lexical Analyzer Generator, M. E. Lesk
Poniżej znajdują się specyfikacje flex-a dla skanerów, które w ciągu znaków pojawiających się na wejściu wyszukują daty w formacie dd.mm.rrrr i wypisują ją na standardowe wyjście. Proszę obejrzeć specyfikację, wygenerować skaner i sprawdzić jego działanie. Następnie proszę obejrzeć wygenerowny kod skanera i odnaleźć w nim fragmenty zawarte w pliku specyfikacji.
Źródła: data1.l | data2.l | test_data
Poniżej znajduje się specyfikacja flex-a dla skanera, który rozpoznaje identyfikatory, liczby całkowite i liczby rzeczywiste oraz wypisuje na wyjście informacje, w której linii pliku wejściowego się znajdują. Proszę obejrzeć specyfikację, wygenerować skaner i sprawdzić jego działanie przy pomocy pliku testowego.
Źródła: identyfikatory.l | test_identyfikatory
Proszę wygenerować skaner, który będzie wyrywać ciągi znaków będące rzeczywistymi datami w formacie dd.mm.rrrr (np. eliminowane są ciągi typu 99.99.9999, poprawna data 01.01.2000 wygląda następująco 1.01.2000).
Można spróbować napisać wyrażenia regularne do rozpoznawania dat w innych formatach (np. daty typu 2/3/2000, 2 Mar 2000, 2 III 2000, itd.).
Proszę wygenerować skaner, który rozpoznaje poprawne identyfikatory, liczby całkowite i liczby rzeczywiste (także w formacie naukowym).
Źródła: test_identyfikatory_2
Proszę przygotować skaner akceptujący zawartość pliku /etc/services, który będzie rozpoznawał poszczególne elementy pliku oraz wyświetlał ich "typ" i "zawartość" (patrz poniżej). Przykładowo:
telnet 23/tcp http 80/tcp www www-http # WorldWideWeb HTTP
Źródła: test_services
Przykładowy wynik działania programu:
nazwa serwisu: telnet numer portu: 23 nazwa protokolu: tcp brak opisu nazwa serwisu: http numer portu: 80 nazwa protokolu: tcp nazwa aliasu: www nazwa aliasu: www-http opis: WorldWideWeb HTTP
W razie wystąpienia błędów składni program powinien wypisać komunikat o błędzie.
Zadanie polega na stworzeniu skanera do analizy logów w formacie tcpdump (tcpdump manual).
Skaner po wczytaniu prawidłowego logu ma wypisywać informację o godzinie, adresie hostów między którymi przesyłane są pakiety oraz o liczbie ewentualnie przesłanych danych, czyli dla wejścia:
11:57:13.923781 IP 149.156.99.111.1791 > 66.102.9.99.80: P 1560712269:1560712573(304) ack... 11:57:13.980726 IP 66.102.9.99.80 > 149.156.99.111.1791: . ack 304 win 7886 11:57:13.981908 IP 66.102.9.99.80 > 149.156.99.111.1791: . ack 304 win 6432 11:57:13.986793 IP 66.102.9.99.80 > 149.156.99.111.1791: P 1431:1636(205) ack 304 win 6432 11:57:13.987073 IP 149.156.99.111.1791 > 66.102.9.99.80: . ack 1 win 65535
ma dawać na wyjściu:
11:57:13 from 149.156.99.111 to 66.102.9.99 304 bytes 11:57:13 from 66.102.9.99 to 149.156.99.111 11:57:13 from 66.102.9.99 to 149.156.99.111 11:57:13 from 66.102.9.99 to 149.156.99.111 205 bytes 11:57:13 from 149.156.99.111 to 66.102.9.99
Linie w nieprawidłowym formacie powinny być pominięte. Proszę sprawdzać poprawność części logu znajdującej się przed :, w tym poprawność godziny i adresu IP (adres może być zbudowany z liczb z zakresu 0-255).
Przyładowy log tcpdump: test-log.