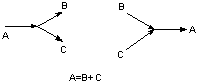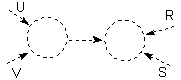 Rys.
1Diagram kontekstowy
Rys.
1Diagram kontekstowy
Skomputeryzowany system czasu rzeczywistego obejmuje:
SCR jest sprzężony z otoczeniem. Jego zadaniem zbieranie danych pochodzących z procesu zachodzącego w otaczającym go środowisku oraz reagowanie na nie z opóźnieniem ustalanym przez dynamikę procesu zachodzącego w otoczeniu. Opóźnienie to może mieć wartość rzędu od kilku mikrosekund do kilku milisekund.
Sprzęt i oprogramowanie wchodzące w skład SCR są bardzo silnie sprzężone. Oba te komponenty realizują wymianę z otoczeniem.
Wymieniane dane mają charakter ciągły lub dyskretny.
Dane ciągłe w czasie mają wartość zdefiniowaną w każdym momencie czasu. Odpowiadają one wartościom fizycznym (temperatura, prędkość, siła). W SCR dane te muszą zostać przetworzone do wartości dyskretnych przez próbkowanie i konwersję A/D. Dane ciągłe mogą mieć nieskończony lub skończony zbiór wartości. Przykładem skończonego zbioru jest zmienna binarna - np.: przycisk monostabliny zwolniony i naciśnięty.
Dane dyskretne w czasie mają skończony zbiór wartości. Są one zdefiniowane w wybranych momentach czasu. Przykładem mogą być sygnały sterujące (nastawy), komendy wysyłane do sterowników cyfrowych (w postaci łańcuchów ASCII), dane przesyłane do wyświetlacza.
Przerwania mają charakter specjalny - nie przenoszą żadnych wartości. Istotne jest ich pojawienie się. Rozróżnialne wartości to ich obecność lub brak obecności.
Bodźce przesyłane z otoczenia do SCR może mieć formę:
Akcje wykonane przez SCR na środowisku w odpowiedzi na bodźce polegać mogą na:
Wymiany danych pomiędzy otoczeniem i systemem odbywają się przy ograniczeniach czasowych. Wydajność systemów może dotyczyć:
W każdym momencie czasu SCR znajduje się w pewnym trybie działania, który determinuje jego obserwowalne zachowanie. Nazywany jest on stanem bieżącym.
Liczba stanów SCR jest skończona (w odróżnieniu od systemów analogowych).
Z punktu widzenia logiki sterowania systemy można podzielić na:
SCR są z natury sekwencyjne
Najogólniejszy podział etapów życia (tworzenia i eksploatacji) SCR jest następujący:
Etap ten obejmuje działania, które zapoczątkowują i mają największy wpływ na proces tworzenia systemu:
Identyfikacja wymagań jest prowadzona w formie dialogu pomiędzy przyszłym użytkownikiem (właścicielem) i realizatorem.
Jej zadaniem jest:
Studium realizowalności obejmuje:
Studium realizowalności może posunąć się do stworzenia wstępnego prototypu systemu.
W ramach studium realizowalności analizowane są: aspekty techniczne, funkcje, wydajność i ograniczenia w celu określenia:
Dla SCR badanie realizowalności ma na celu przede wszystkim oszacowanie czasów przetwarzania, czasów odpowiedzi, prędkości transmisji danych oraz zużycia zasobów.
Rezultat powyższych analiz po dołączeniu informacji dotyczących kosztów, źródeł zaopatrzenia w sprzęt i oprogramowanie, wymagań jakościowych formułowany jest w postaci dokumentu.
Zapis wymagań oraz studium realizowalności stanowi punkt wyjścia dla dalszego rozwoju systemu.
Fazy te obejmują:
Specyfikacja wymagań jest to opis techniczny wymagań, które system ma spełnić. Jest to zapis częściowo formalny, który pozwala opisać otoczenie i zachowanie systemu bez brania pod uwagę założeń technicznych (informatycznych). Specyfikacja wymagań powinna dawać odpowiedź na pytanie: co system ma robić.
Faza projektowania ma na celu zaproponowaniu architektury systemu oraz architektury jego komponentów a także ustalenie zasad konstrukcji systemu. Projekt powinien odpowiedzieć na pytanie: jak wykonać system.
Zazwyczaj faza projektowania dzielona jest na dwa etapy:
Przejście pomiędzy fazą specyfikacji i projektowania wymaga:
Konstrukcja systemu obejmuje:
Integracja systemu polega na scalaniu elementów oprogramowania i sprzętu w docelowym otoczeniu.
Walidacja systemu polega na sprawdzeniu, czy jest on zgodny z wymaganiami sformułowanymi przez użytkownika (właściciela).
| specyfikacja wymagań | |||||
| projekt wstępny | |||||
| projekt szczegółowy | |||||
| implementacja i testy | |||||
| integracja | |||||
| walidacja |
Model kontroli jakości
| specyfikacja wymagań | walidacja | |||||
| projekt wstępny | integracja | |||||
| projekt szczegółowy | testy | |||||
| konstrukcja |
Specyfikacja jest procesem, w którym tworzony jest abstrakcyjny opis systemu. Zadaniem jej jest znalezienie reprezentacji podstawowych własności i aspektów działania systemu pozbawionej szczegółów technicznych.
Proces redukcji, a następnie rozszerzania opisu systemu nosi nazwę modelowania, w wynikowa reprezentacja nazywana jest modelem.
Pomocnym narzędziem jest hierarchizacja opisów. Zadaniem hierarchizacji jest zarządzanie złożonością opisów. Tworzenie specyfikacji ma charakter procesu wieloetapowego:
Zbiór wszystkich tych opisów, w połączeniu z interfejsami obejmuje system w całej jego złożoności.
Model logiczny rozumiany jest jako opis tego, co system ma robić; model fizyczny jako specyfikacja, w jaki sposób ma to zostać zrealizowane.
Model fizyczny obejmuje aspekt technologiczny jego realizacji, a także osoby, obiekty fizyczne, dokumenty.
Model logiczny obejmuje:
Opisy funkcjonalny i informacyjny są wspólne dla wszystkich systemów informatycznych.
Opis zdarzeniowy jest charakterystyczny dla SCR, które muszą reagować na sygnały pochodzące z otoczenia i realizować transformacje danych w zależności od stanu elementów sterujących.
Przedmiotem zainteresowania będzie aspekt technologiczny modelu fizycznego (oprogramowanie).
Diagramy przepływów danych (DFD)
SART Ward-Mellor
SART Hatley-Pirbhai
Diagramy ERD
Opis funkcjonalny SCR obejmuje funkcje, które system powinien pełnić oraz informacje, które powinien przetwarzać bez bezpośrednich odwołań do uwarunkowań technologicznych.
Obejmuje on:
Analiza strukturalna proponuje formalne narzędzie modelowania, które pozwala na
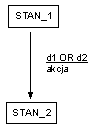
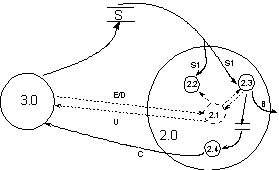
Diagram kontekstowy Błąd! Nieznany argument przełącznika.:
Granica jest wyznaczona przez elementy należące do otoczenia, z którymi system wymienia dane. Stanowią one brzeg modelu.
Rys.
1Diagram kontekstowy
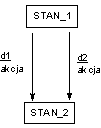
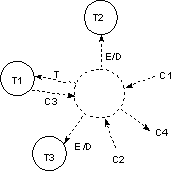
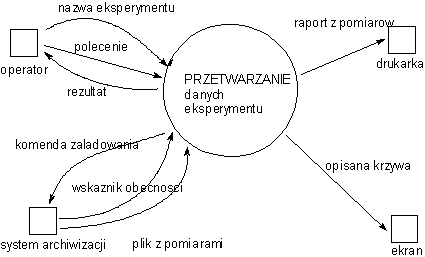
Diagram wstępny (Błąd! Nieznany argument przełącznika.) pokazuje pierwszy poziom dekompozycji podstawowej funkcji użytkowej systemu.
System dzielony jest na procesy, pomiędzy którymi krążą przepływy danych. Mogą one docierać bezpośrednio (polecenie_wydruku ) lub być magazynowane (surowe pomiary, typ pomiarów).
 Rys.
2 Diagram wstępny
Rys.
2 Diagram wstępny
Każdy z procesów ma funkcję podstawową: ODSEPARUJ surowe pomiary, SPORZĄDŹ raport, WIZUALIZUJ krzywą.
Procesy te mogą zostać dalej zdekomponowane. Błąd! Nieznany argument przełącznika. i Błąd! Nieznany argument przełącznika. pokazują dekompozycję procesów 6.0 i 7.0
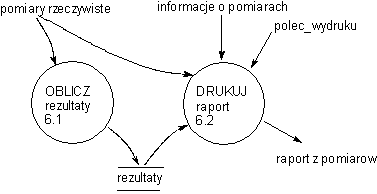 Rys.
3 Dekompozycja procesu
6.0
Rys.
3 Dekompozycja procesu
6.0
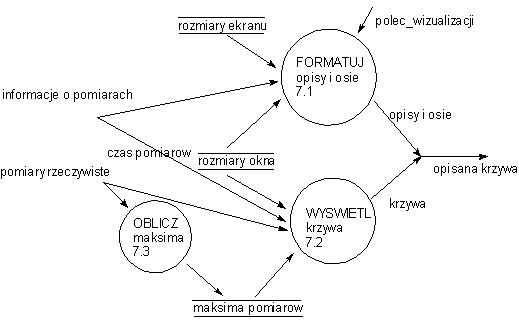 Rys.
4 Dekompozycja procesu
7.0
Rys.
4 Dekompozycja procesu
7.0
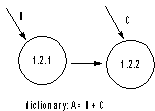
Poprzedni przykład pokazuje cztery elementy występujące w DFD: przepływy danych, procesy, magazyny danych i elementy terminalne
Przepływ danych
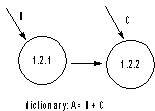
Definicja Przepływ danych pokazuje drogę, po której dane przemieszczają się pomiędzy miejscami transformacji. Może zawierać dane proste (pierwotne) lub złożone (np.: informacje o pomiarach zawierają daną składową czas pomiarów) Każda z danych może być interpretowana jako informacja, materia lub energia.
Reprezentacja Strzałka etykietowana identyfikatorem danych. Identyfikator danych powinien mieć formę rzeczownika z przymiotnikami i nie powinien implikować w żaden sposób przetwarzania.
Proces
Definicja Proces jest elementem działania realizowanym przez system. Proces transformuje co najmniej jedne przepływ danych wejściowych w co najmniej jeden przepływ danych wyjściowych. Proces konsumuje, przetwarza, składuje i produkuje przepływy danych.
Reprezentacja Okrąg otaczający identyfikator procesu i numer referencyjny. Identyfikator procesu powinien opisywać wykonywaną transformację używając czasownika (w trybie rozkazującym lub bezokoliczniku) z dopełnieniem określającymi typ przetwarzanych.
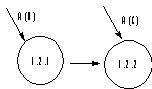
Numer referencyjny identyfikuje miejsce danego procesu w hierarchii powstałej w wyniku dekompozycji.
Magazyn danych
Definicja magazyn danych reprezentuje daną prostą lub zgrupowanie danych, które jest stale dostępne dla wszystkich procesów danego poziomu i niższego. Zawartość magazynu może zostać zmodyfikowana jedynie przez proces dokonujący zapisu.
Reprezentacja Dwie linie równoległe otaczające identyfikator. Zasady nazewnictwa analogiczne, jak dla przepływów danych.
Elementy terminalne (granice modelu)
Definicja Element terminalny reprezentuje obiekt umieszczony w otoczeniu systemu, który stanowi źródło lub jest adresatem przepływów danych wymienianych pomiędzy systemem i jego zewnętrznym środowiskiem. Może opisywać urządzenie peryferyjne, czujnik, siłownik, osobę lub inny system.
Reprezentacja Prostokąt otaczający identyfikator. Nazwa elementu powinna odzwierciedlać rolę, jaką pełni on w systemie.
Dopuszczalne połączenia
| proces | magazyn | symbol terminalny | |
| proces | wymagana nazwa | domyślnie przyjmowana jest nazwa magazynu | wymagana nazwa |
| magazyn | domyślnie przyjmowana jest nazwa magazynu | ||
| symbol terminalny | wymagana nazwa |
Uproszczenia w reprezentacji
Uproszczenia w reprezentacji dotyczą magazynów i przepływów danych.
| A rozdziela się na B i C
B i C łączą się w A |
|
| Pominięcie identyfikatora domyślnego przepływu |
|
| Pominięcie identyfikatora domyślnego przepływu |
|
| Pominięcie identyfikatora domyślnego przepływu |
|
| Pominięcie identyfikatora domyślnego przepływu |
|
| Przepływ dwukierunkowy |
|
| Niezależne dane, które biegną pomiędzy tymi samymi elementami diagramu |
Dopuszczalne jest powtórzenie na schemacie symbolu magazynu lub symbolu terminalnego po dodaniu gwiazdki do identyfikatora.
|
|
|
Reguły interpretacji DFD ustalają domyślną semantykę modelu.
Reguła aktywacji. Warunkiem wkw. aktywacji procesu jest obecność wszystkich danych wejściowych. W wyniku aktywacji procesu pojawiają się dane wyjściowe.
Reguła konsumpcji. Dane przenoszone przez przepływ danych są konsumowane przez proces je wykorzystujący (w kolejności nadejścia) i następnie znikają po użyciu. Magazyny danych przechowują dane w sposób trwały. Po odczycie są dostępne do odczytu dla dalszych procesów. Magazyny pozostają niezmienione aż do następnego zapisu.
Brak jest szczególnych założeń dotyczących wartości początkowych magazynów.
W niektórych zastosowaniach jest to konwencja niewygodna. Czasem rozróżnia się magazyny nie wyczerpywane i wyczerpywane (np.: kolejki FIFO).
Standardowo jednak magazyny należy interpretować jak dzielony plik w problemie czytelników i pisarzy.
Reguła zachowania Jedynie te przepływy opuszczają proces, które można stworzyć na podstawie przepływów wejściowych. (Np. polecenie wizualizacji albo polecenie wydruku).
Reguła konieczności Proces akceptuje tylko te przepływy wejściowe, które są niezbędne do wytworzenia przepływów wyjściowych. (Tu tylko podzbiór danych element)
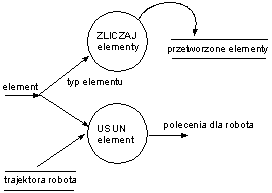
Reguła autonomii Proces akceptuje dane wejściowe i produkuje dane wyjściowe bez rozróżnienia ich pochodzenia i przeznaczenia.
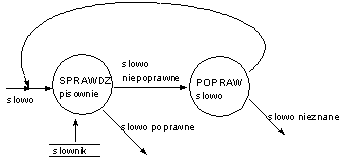
Diagram kontekstowy reprezentuje szczyt hierarchii. Składa się wyłącznie z jednego procesu, którego nazwa odzwierciedla podstawową funkcję systemu.
Jest to jedyny diagram, na którym pojawiają się elementy terminalne reprezentujące interfejsy pomiędzy systemem i otoczeniem.
Warstwy dekompozycji Diagram pierwszego poziomu nazywany jest diagramem wstępnym. Pokazuje on dekompozycję systemu na podsystemy, które odpowiadają podstawowym funkcjom systemu oraz na ich interfejsy.
Każdy podsystem jest z kolei traktowany jako system i dalej iteracyjnie dekomponowany na podsystemy.
Przy przejściu pomiędzy poziomami następuje dekompozycja procesu wyższego poziomu na podprocesy. Rezultat dekompozycji zapisany jest w formie diagramu DFD. Proces dekomponowany nazywany jest rodzicem, diagram DFD - diagramem potomnym.
Dekompozycji procesu towarzyszy odpowiednia transformacja kontekstu - czyli przepływów danych, które proces czyta lub tworzy. Grupy danych mogą być dekomponowane na podgrupy lub dane pierwotne.
Każdy poziom diagramu DFD nosi nazwę i numer referencyjny procesu rodzica. Każdy proces posiada numer, którego przedrostkiem jest numer rodzica, natomiast przyrostkiem numer procesu na diagramie. (Reguła ta nie stosuje się do diagramu pierwszego poziomu.)
DFD danego poziomu zawiera jedynie te informacje (procesy, magazyny i przepływy), które są niezbędne do zapewnienia pełnej reprezentacji, lecz bez zbędnych szczegółów.
Przepływy danych i magazyny
istniejące wewnątrz dekomponowanego procesu są
niewidoczne na wyższej warstwie. Są one maskowane na
danym poziomie i odkrywane przy przejściu do niższego
poziomu.
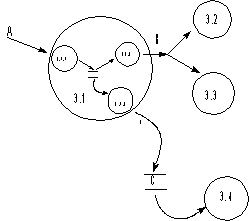 Rys. 5Diagram
procesu 3.0
Rys. 5Diagram
procesu 3.0
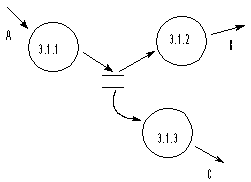 Rys. 6
Dekompozycja procesu 3.1
Rys. 6
Dekompozycja procesu 3.1
Przejście pomiędzy poziomami powoduje, że diagram potomny zawiera dokładnie te same przepływy wejściowe i wyjściowe, które miał proces rodzicielski.
Zachowanie przepływów danych jest ustalane na podstawie użycie tych samych nazw (identyfikatorów).
Podczas hierarchizacji wprowadza się dodatkowe reguły syntaktyczne dotyczące przepływów danych. Może nastąpić rozbijanie danych podczas przejścia pomiędzy poziomami.
|
|
|
|
[+magazyn]
Rezultatem dekompozycji jest osiągnięcie poziomu, gdzie dalsza dekompozycja nie jest już prowadzona. Pojawiające się tam procesy nazywane są procesami prymitywnymi (pierwotnymi).
Wymagają one odrębnej specyfikacji - stąd najniższy poziom dekompozycji nosi nazwę warstwy specyfikacji procesów.
Specyfikacja procesów wymaga opisu w jaki sposób tworzona jest informacja wyjściowa na podstawie informacji wejściowej. Opis ten powinien obejmować wszystkie wejścia, nie zawierać niejednoznaczności i wskazań implementacji.
Specyfikacja procesów wykorzystuje przepływy i magazyny danych. Wszystkie dane powinny być zawarte w słowniku danych.
Istnieje kilka sposobów specyfikacji procesów:
Specyfikacja proceduralna podaje w opisowy sposób algorytm, który jest używany do wytworzenia danych wyjściowych.
Polega ona na:
Przykład specyfikacji procesu
Proces POBIERZ dane eksperymentu
Wydaj
IF THEN
przypisz
zapisz ELSE
przypisz ENDIF
zwróć |
Specyfikacja za pomocą prewarunków i postwarunków
Specyfikacja ta pokazuje relacje przyczynowe pomiędzy przepływami wejściowymi i wyjściowymi, opisuje warunki konieczne powstania danych na wyjściu, bez wchodzenia w szczegóły przetwarzania
Przykład specyfikacji:
| PRE | nazwa eksperymentu jest wprowadzona
|
| POST | komenda zaladowania jest wydana
|
| PRE | wskaznik obecności ma wartość TRUE AND
|
| POST | rezultat ma wartość SUKCES AND
|
| PRE | wskaznik obecności ma wartość FALSE
|
| POST | rezultat ma wartość PORAŻKA
|
Inne rodzaje specyfikacji
Specyfikacja tabelaryczna pokazuje
w tabeli zależności pomiędzy wartościami
danych na wejściu i wyjściu
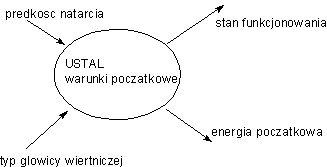
| wejścia | wyjścia | ||
| typ głowicy wiertniczej | prędkość natarcia | stan funkcjonowania | energia poczatkowa |
| 7.5 J | 0.9
1.1 | dobry | 0.5 |
| 7.5 J | 1.1
0.9 | zły | nie określona |
| 15 J | 1.9
2.1 | dobry | 4 |
| 15 J | 2.1
1.9 | zły | nie określona |
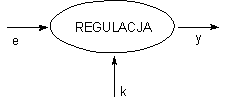
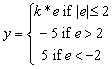
IN: e (błąd), k (współczynnik wzmocnienia)
OUT: y (sterowanie)
OPIS: Proces wyznacza sterowanie
y na podstawie wartości błędu e
Opis funkcjonalny koncentruje się na sposobie przetwarzania danych. Opis zdarzeniowy dotyczy:
Opis zdarzeniowy jest związany z modelowaniem systemu jako maszyny zawierającą skończoną liczbę stanów. Przyjmuje się, że w danym momencie system znajduje się w jednym ze stanów określających jego przyszłe obserwowalne zachowanie.
Pojawienie się zdarzeń lub pewnych kombinacji zdarzeń wywołuje akcje i generację innych zdarzeń, a tym samym wywołuje zmianę stanu systemu.
Narzędzie modelowania cech zdarzeniowych powinno pozwalać na
Zdarzenie jest to informacja, która pojawia się w pewnym momencie i oznacza, że "coś się stało". Zdarzenie może być zdarzeniem prostym lub kombinacją zdarzeń prostych.
Jeżeli proces transformujący dane wykorzystuje dane ciągłe, wówczas osiągnięcie pewnego progu lub przedziału wartości może powodować generację zdarzenia prostego.
Identyfikator takiego zdarzenia
ma zwykle postać "temperatura>100°",
"predkosc < 5m/s",
"przycisk_wcisniety = true"
W przypadku, kiedy wykorzystywane
są dane dyskretne w czasie, źródłem zdarzenia
może być pojawienie się danej lub pojawienie
się i przyjęcie przez nią jednej z wartości,
np.: "wprowadzona_częstotliwość_próbkowania",
"kod_poprawny=true".
Decyzja, czy wartość dyskretna w czasie powinna być traktowana jak zdarzenie, czy też jako dana zależy od jej użycia w systemie.
Przykład
kod_poprawny
może być traktowana jako przepływ danych, który
przyjmuje dwie wartości - true i false. Wartości
te mogą być używane przez proces transformujący
dane w celu obliczania liczby autoryzowanych dostępów
i prób wejścia bez autoryzacji.
kod_poprawny=true"
oraz "kod_poprawny=false".
Możliwe jest także inne
podejście. Informacja kod_poprawny
jest traktowana jako dana, natomiast zmiana (ustawienie) wartości
powoduje generację zdarzenia kod_poprawny_zmieniono.
W reakcji na to zdarzenie
system powinien odczytać nową wartość zmiennej
(danej).
Zdarzenia mogą wywoływać wewnętrzne akcje, które zmieniają stan procesów transformujących dane. Zasadniczo, akcje te polegają na aktywacji i deaktywacji pewnego procesu.
Rozróżnia się trzy podstawowe typy akcji:
Czasem rozróżnia się szczególne rodzaje zezwolenia i zabronienia: suspend <S> zawiesza przetwarzanie bez niszczenia tymczasowych rezultatów; resume <R> reaktywuje proces zatrzymany za pomocą suspend.
Jest kwestią umowną, jak traktować poszczególne akcje. Akcja enable może inicjować proces, akcja disable usuwać proces, suspend zawieszać bez usuwania, resume reaktywować bez powtórnej inicjalizacji.
Dobrym przykładem jest OSWIETLENIE - proces transformujący energię elektryczną w energię świetlną:
W przykładzie bardziej zwiazanym z oprogramowaniem:
Celem modelu logicznego jest abstrahowanie od tego typu szczegółów i pozostawienie pewnej swobody implementacji.
Mechanizm prowokowania zdarzeń i akcji na podstawie pewnej kombinacji pojawiających się zdarzeń nazywany jest logiką sterowania.
Logika sekwencyjna. Jeżeli wyjścia logiki sterowania są funkcją bieżącego stanu systemu i bieżących zdarzeń wejściowych - logika ta nazywana jest logiką sekwencyjną. Ponieważ bieżący stan systemu jest rezultatem ostatnich zdarzeń wejściowych, logika sekwencyjna implikuje konieczność istnienia pamięci, która przechowuje pewną ścieżkę działania systemu. Stan systemu odpowiada więc pewnemu wewnętrznemu stanowi pamięci jego logiki sterowania.
Logika kombinatoryczna. Jeśli wyjścia są jedynie funkcją bieżących wejść, wówczas logika sterowania nazywana jest kombinatoryczną i nie musi mieć żadnej pamięci.
Zazwyczaj logika sterowania SCR jest logiką sekwencyjną, ale pewne jego podsystemy mogą zadowalać się logiką kombinatoryczną.
Metody Warda-Mellora (WM) i Hatleya-Pirbhai (HP) proponują rozszerzenia do Analizy Strukturalnej uwzględniające aspekt zdarzeniowy.
Rozszerzenia te obejmują:
Przykład
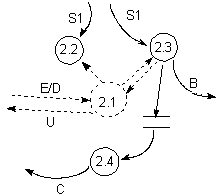
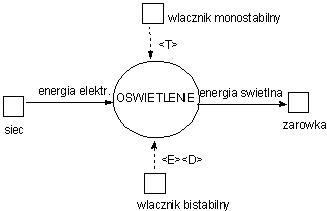
Diagram (w notacji Warda-Mellora) pokazuje proces, którego zadaniem jest sterowanie amplitudą sygnału dźwiękowego. Ciągły przepływ danych sygnał dźwiękowy przetwarzany jest na sygnał po regulacji.
Regulacja amplitudy uaktywnia się w przypadku przekroczenia progów maksymalnego lub minimalnego.
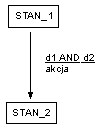
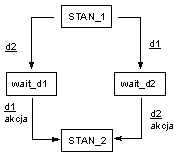
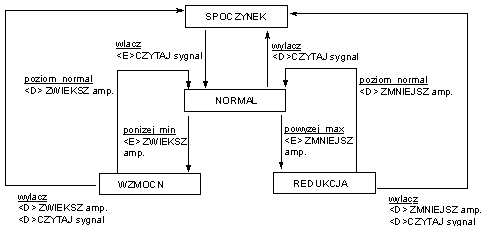
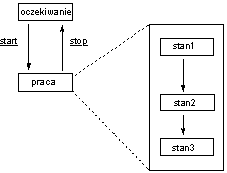
W logice sekwencyjnej reakcja na bodźce zależy od bieżącego stanu sterowania. Opis sterowania prowadzony jest z wykorzystaniem maszyn skończenie stanowych.
Analizując powyższy przykład wyodrębnimy trzy stany pracy:
oraz
Definicja maszyny może być podana w postaci tabeli stanów i przejść lub w postaci diagramu.
Specyfikacja tabelaryczna (tabela stanów i przejść)
M={S, I, O, FS, FO, s0) Fs SIS, Fs SIO
| stan (S) | warunek (I) | akcja (O) | następny stan |
| SPOCZYNEK | wlacz | <E>czytaj sygnal | NORMALNY |
| NORMALNY | wylacz | <D> CZYTAJ sygnal | SPOCZYNEK |
| NORMALNY | ponizej_min | <E>ZWIEKSZ amplitude | WZMOCN |
| NORMALNY | powyzej_max | <E>ZMNIEJSZ amplitude | REDUKCJA |
| WZMOCN | wylacz | <D> ZWIEKSZ amplitude
<D> czytaj sygnal | SPOCZYNEK |
| WZMOCN | poziom_normal | <D> ZWIEKSZ amplitude | NORMAL |
| REDUKCJA | wylacz | <D> ZMNIEJSZ amplitude
<D> CZYTAJ sygnal | SPOCZYNEK |
| REDUKCJA | poziom_normal | <D> ZMNIEJSZ amplitude | NORMAL |
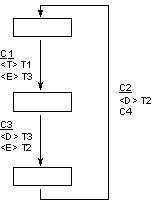
Analogiczne zależności opisuje poniższy diagram stanów i przejść
Przejście
Ogólna postać przejścia jest następująca:
Zasady interpretacji
System oczekuje na zdarzenie wejściowe w danym stanie. Po pojawieniu się zdarzenia odpowiadającego dozorowi następuje przejście.
W przypadku pojawienia się zdarzenia, dla którego w danym stanie brak jest dozoru - zdarzenie jest ignorowane.
W przypadku pętli prowadzącej do stanu wyjściowego - system w reakcji na zdarzenie wejściowe wykona akcję, lecz nie będzie ona powodowała zmiany stanu
W przypadku, kiedy zdarzenia wejściowe połączone są operatorem koniunkcji, zakładamy, że powinny mieć one miejsce równocześnie lub system czeka na pojawienie się wszystkich wymaganych zdarzeń.
|
|
|
W przypadku, kiedy zdarzenia wejściowe połączone są operatorem alternatywy - wystarczy jedno z nich, aby dokonać przejścia.
|
|
| |
Przykład pokazuje automatyczną kasę do sprzedaży biletów.
Obiekt odpowiedzialny za logikę sterowania jest przedstawiony w postaci pionowej pogrubionej linii. Akcje odpowiedzialne za aktywacje lub deaktywację procesów nie są uwidaczniane na diagramie. Umieszcza się je w tabeli aktywacji procesów.
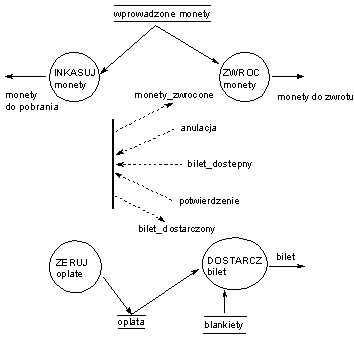
Wiersze tabeli aktywacji procesów pokazują odwzorowanie kombinacji zdarzeń wejściowych w akcje aktywacji procesów, a także w zdarzenia wyjściowe.
Brak aktywności procesu oznaczony jest przez 0, aktywność przez liczbę dodatnią (1,2...). Liczby opisują kolejność aktywacji procesów.
Uzupełnieniem opisu funkcjonalnego i zdarzeniowego jest opis przetwarzanych danych. W klasycznych programach dane przetwarzane przez system mogą być:
W systemach czasu rzeczywistego uwzględnia się także aspekt czasowy:
W klasycznym podejściu Analizy Strukturalnej (DeMarco) dane definiuje się z wykorzystaniem notacji Backusa-Naura.
| Symbol | Znaczenie |
| = | zdefiniowane jako |
| + | zgrupowanie (bez określonego porządku) |
| [|] | albo - wyliczenie możliwych wartości |
| {} | iteracja bez zakresów |
| n{}p | iteracja od n do p |
| n{} | iteracja - co najmniej n |
| {}p | iteracja od 0 do p |
| n{}n | iteracja - dokładnie n |
| " " | ograniczniki literału |
| * * | komentarz |
| @ | oznacza klucz przy definicjach iteracyjnych |
Przykłady:
| polecenie | = [polec_wydruku | polec_wizualizacji] |
| dane eksperymentu | = info o pomiarach + surowe pomiary |
| surowe pomiary | = 1 {@moment + surowy pomiar } 4096 |
| surowy pomiar | = 12 {@numer_bitu+wartosc_bitu}12 |
| numer_bitu | =[1|2|.....9|10|11|12] |
| wartosc_bitu | =[1|0] |
Dane pierwotne są scharakteryzowane przez:
Przykład:
| moment | = * moment czasowy w którym przeprowadzono pomiar *
* typ: całkowity, przedział 1-4096, jednostka s * |
Słownik danych zawiera specyfikacje wszystkich przepływów i magazynów, które występują w diagramach DFD oraz specyfikacjach procesów.
Słownik danych pełni rolę bazy danych z nazwami identyfikatorów i ich definicjami. Jego zadaniem jest zapewnienie spójności pomiędzy różnymi poziomami hierarchii opisu funkcjonalnego (i zdarzeniowego).
Spójność dotyczy:
w przypadku rozbicia przepływu danych na części składowe przy przejściu pomiędzy dwoma poziomami hierarchii - opierając się na definicji danych zawartej w słowniku ustala się poprawność tej operacji
|
|
|
W metodologii WM model logiczny nazywany jest modelem podstawowym (ang. essential ) natomiast model fizyczny modelem implementacji.
Model implementacji rozszerza model podstawowy (logiczny) wprowadzając do niego szczgóły techniczne zapewniające implementację systemu dla wybranej technologii sprzętu i oprogramowania. Stanowi więc odwzorowanie modelu logicznego na pewną platformę technologiczną.
Metodologia WM odróżnia informacje będące nośnikiem wartości od informacji, które są istotne ze względu na sam fakt ich wystąpienia.
Dane stanowią informacje będące nośnikiem wartości. Dzielą się one na dane:
Dana dyskretna w czasie ma dwa elementy składowe: skończony zbiór wartości oraz czas jej pojawienia się.
Dane nie będące nośnikiem wartości są z natury dyskretne. Ich rola w systemie redukuje się do samego faktu wystąpienia (obecności lub nie obecności).
Zdarzenie jest informacją nie przenoszącą wartości. Traktowane jest jak sygnał pochodzący z otoczenia (np.: przerwanie sprzętowe) lub sygnał generowany przez proces transformujący dane (np.: przerwanie programowe).
Zdarzenie ma charakter przejściowy (ulotny). Aby być dostępne w sposób bardziej trwały, powinno być przechowywane w magazynie zdarzeń.
Model podstawowy obejmuje opis funkcjonalny wzbogacony o opis zdarzeniowy. Specyfikuje on:
Diagramy modelu podstawowego stanowią rozszerzenie DFD i nazywane są schematami transformacji (ST). Są one również hierarchiczne, podobnie jak DFD.
Model podstawowy zawiera:
Model podstawowy składa się z dwóch modeli:

Przepływy danych Wzbogacone są o rozróżnienie pomiędzy danymi ciągłymi i dyskretnymi w czasie
|
| dane ciągłe |
|
| dane dyskretne |
Elementami służacymi opisowi aspektu zdarzeniowego są:
Przepływ zdarzeń reprezentuje drogę, po której przesyłane są zdarzenia pomiędzy procesami transformujacymi dane i transformacjami sterowania.
![]()
Magazyn zdarzeń reprezentuje obiekt zdolny przechowywać (buforować) zdarzenia. Dzięki temu zdarzenia stają się trwale dostępne dla wszystkich transformacji, które mogą ich potrzebować.
W odróżnieniu od magazynów danych - magazyn zdarzeń może otrzymywać zdarzenia bezpośrednio z otoczenia, bez konieczności buforowania ich przez proces. (W praktyce taki proces będzie jednak występował - w postaci procedury obsługi przerwań.)
![]()
Transformacja sterowania reprezentuje jednostkę sterującą (proces sterujący), która wyznacza zdarzenia wyjściowe na podstawie zdarzeń wejściowych. Nie realizuje ona przetwarzania zdarzeń wejściowych w sensie proceduralnym.
Z zasady transformacje sterowania opierają się na logice sekwencyjnej, stąd najczęściej reprezentowane są w postaci diagramów stanów i przejść lub tabel.
Podobnie, jak dla przepływów danych reprezentowana jest w postaci okręgu, w którym umieszczona jest nazwa i numer referencyjny

Nazwa transformacji ma zazwyczaj postać "sterowanie" lub "steruj", "kontroluj", "zarządzaj" z dopełnieniami określającymi sterowany element systemu.
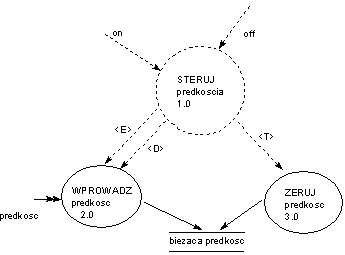
Aktywatory procesów
są zdarzeniami, które skierowane są do procesów
transformujących dane. Ich zadaniem jest zmiana stanu tych
procesów. Oznaczane są przez <E>nable (aktywacja),
<D>isable (zawieszenie), <T>rigger (jednorazowe uruchomienie).
Są to zawsze zdarzenia generowane przez proces sterujący.
Standardowo, nie nadaje się im nazw, lecz specyfikuje rodzaj
akcji: <E>,<D> oraz <T>. Domyślnie nazwą
zdarzenia jest rodzaj akcji + nazwa jej adresata, np.: <T>
ZERUJ predkosc, <E>
WPROWADZ predkosc
Poniższe reguły tworzenia diagramów w metodyce WM rozszerzają standardową składnię diagramów DFD.
Poniższa tabela opisuje możliwe
połączenia
| transformacja danych | transformacja sterowania | magazyn danych | magazyn sterowania | element terminalny | |
| transformacja danych |
|
|
|
|
|
| transformacja sterowania | E/D/T | E/D/T
|
| ||
| magazyn danych |
| ||||
| magazyn sterowania |
| ||||
| element terminalny |
|
|
|
Diagram schematów transformacji może nie zawierać transformacji sterowania lub zawierać ich kilka. Pozwala to na rozproszenie sterowania.
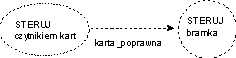
Model zachowania obejmuje diagram wstępny i diagramy, na których specyfikowana jest dekompozycja transformacji danych. Dany poziom hierarchii opisywany jest przez schemat transformacji zawierający przepływy danych, zdarzeń, magazyny danych i zdarzeń, transformacje danych i transformacje sterowania.
| Transformacje 2.0 i 3.0 przed dekompozycją | Diagram pokazujący dekompozycję transformacji 2.0 |
|
|
|
Hierarchizacja sterowania pozwala zdekomponować logikę sterowania i przypisać jej elementy kolejnym poziomom schematów transformacji.
Hierarchizacja pociąga za sobą następujące reguły interpretacji:
W metodzie WM preferowaną formą specyfikacji prymitywnych transformacji danych jest podanie prewarunków i postwarunków. Dopuszczalne jest każda forma specyfikacji, która w jednoznaczny sposób poda odwzorowanie pomiędzy przepływami wejściowymi li wyjściowymi.
W metodzie WM podstawowym narzędziem opisu logiki sterowania są maszyny skończenie stanowe opisane za pomącą diagramów przejść i stanów.
Opuszczenie danego stanu jest możliwe po otrzymaniu sygnału ( po pojawieniu się zdarzenia). Podczas przejścia emitowane są zdarzenia wyjściowe - mogą być nimi także akcje aktywujące procesy E/D/T.
|
|
|
Dekompozycja sterowania
Schematy transformacji pociągają za sobą dekompozycję sterowania:
|
| |
Wymaganie spójności modelu obejmuje zgodność następujących elementów:
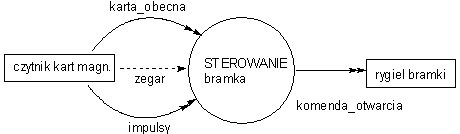
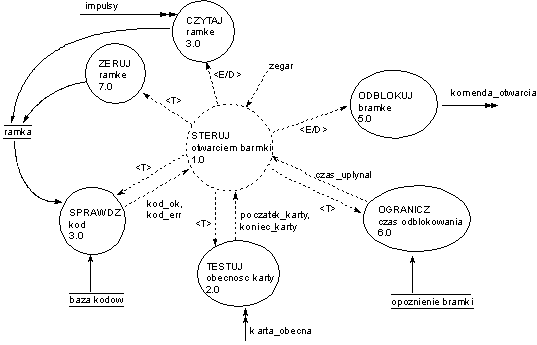
Poniższy przykład pokazuje elementy specyfikacji WM dla prostego systemu sterującego odblokowaniem drzwi za pośrednictwem karty magnetycznej. Podobne systemy można napotkać w przedsiębiorstwach (karta identyfikuje pracowników posiadających prawo wejści do danej strefy) lub w całodobowych bankomatach umieszczonych wewnątrz budynków (karta bankowa umożliwia dostęp do bankomatu poza godzinami funkcjonowania placówki).
Elementami terminalnymi systemu są:
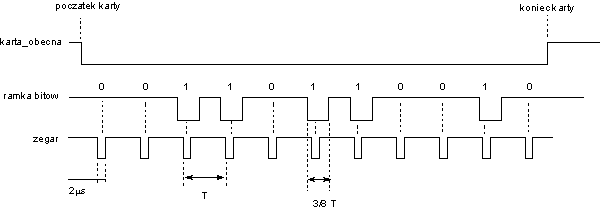
W zależności od prędkości przesuwu czytnik dobiera prędkość taktowania zegara, który jest używany do dekodowania zapisu na ścieżce magnetycznej.
Dla prędkości przesuwu karty V zawartej w przedziale [10 cm/s - 150 cm/s] oraz założonej gęstości zapisu 75bpi (2.95 bit/mm) )okres zegara wynosi 3.4 ms - 226 s
T
= 0.34/V
Przepływy danych
Uwaga - przykład jest tak dobrany, aby schemat transformacji diagramu wstępnego nie podlegał dalszej dekompozycji.
2.0 TESTUJ obecnosc karty
| PRE | wykryte opadające zbocze sygnału karta obecna |
| POST | wyślij sygnał początek karty |
| PRE | wykryte wznoszące zbocze sygnału karta obecna |
| POST | wyślij sygnał koniec karty |
3.0 CZYTAJ ramkę
| PRE | brak |
| POST | bity są umieszczone w magazynie ramka |
4.0 SPRAWDZ kod
| PRE | ramka zawiera znacznik konca AND kod karty nie jest pusty
AND kod karty należy do bazy kodów |
| POST | wyślij sygnał kod_ok |
| PRE | ramka zawiera znacznik konca AND kod karty nie jest pusty
AND kod karty NIE należy do bazy kodów |
| POST | wyślij sygnał kod_err |
| PRE | ramka zawiera znacznik konca AND kod karty jest pusty |
| POST | wyślij sygnał kod_err |
5.0 ODBLOKUJ bramkę
| PRE | brak |
| POST | wyślij komendę otwarcia |
6.0 OGRANICZ czas odblokowania
| PRE | lokalny czas = opoznienie bramki |
| POST | wyślij czas uplynal |
7.0 ZERUJ ramkę
| PRE | brak |
| POST | ramka jest pusta |
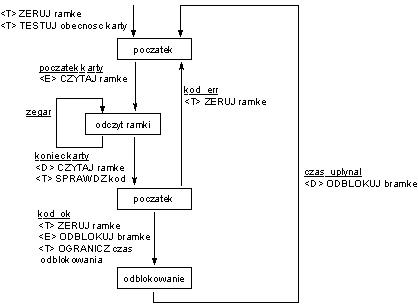
Jedynie proces 1.0 wymaga specyfikacji w postaci diagramu stanów i przejść.
Przejście początkowe uruchamia proces ZERUJ ramkę oraz TESTUJ obecność karty. Zauważmy, że z diagramu wynika, że transformacja TESTUJ obecność karty nigdy nie kończy działania.
karta obecna | * sygnał zwnętrzny pochodzący z czytnika *
|
zegar | * sygnał uzywany do próbkowania danych czytanych z karty *
|
impulsy | * zapis danych na ścieżce karty *
|
komenda otwarcia | * napiecie powodujace otwarcie rygla 0 - blokad 12V odblokowanie*
|
ramka | = znacznik początku + komunikat + znacznik końca
|
znacznik początku | * typ znakowy, kodowanie 010111 *
|
znacznik konca | * typ znakowy, kodowanie 01111 *
|
komunikat | =5{znak kontrolny}5
|
znak kontrolny | =bit parzystosci+znak numeryczny
|
znak numeryczny | =4{bit}4
|
bit | = [0|1]
|
bit parzystości | = [0|1]
|
poczatek_karty | * zdarzenie oznaczajace wprowadzenie karty do czytnika*
|
koniec_karty | * zdarzenie oznaczajace opuszczenie czytnika przez kartę*
|
kod_ok | * zdarzenie generowane po rozpoznaniu kodu karty *
|
kod_ok | * zdarzenie generowane w przypadku blędu odczytu karty lub po stwierdzenieu nieprawidłowego kodu *
|
czas uplynal | * zdarzenie generowane po odblokowaniu bramki w celu jej powtórnego zablokowania *
|
opoznienie bramki | * okres czasu podczas którego drzwi są odblokowane *
|
| zdarzenie wejściowe | zdarzenie wewnętrzne | akcja wyjściowa | czas odpowiedzi |
| początek karty | początek komendy otwarcia | 1.5 s dla prędkości minimalnej przesuwu karty V = 10 cm/s
0.57 s dla prędkości maksymalnej V = 150 cm/s | |
| czas_uplynal | koniec komendy otwarcia | 0.5 s max |