Niniejsze opracowanie ma charakter skrótowego przewodnika dla użytkowników USK AGH. Informacje podane tutaj były aktualne w chwili pisania, co nie znaczy, że są aktualne nadal - tempo zmian w tym zakresie jest bardzo szybkie, zwłaszcza jeśli chodzi o oprogramowanie Public Domain realizujące poszczególne usługi. W miarę potrzeby, będą ukazywać się znowelizowane wersje tego tekstu. Bardziej szczegółowe informacje o wymienionych tu usługach i protokołach, o sieci Internet jako takiej oraz o systemie operacyjnym Unix można znaleźć w literaturze, jak również w różnego rodzaju dokumentach dostępnych w sieci - kilka z nich wyliczam na końcu tego tekstu.
USK AGH jest siecią multiprotokolarną i możliwe jest korzystanie z protokołów transmisji takich jak DECnet czy Novell IPX na komputerach podłączonych do USK (w ramach sieci lokalnych). Ponieważ jednak UCI AGH oferuje wyłącznie usługi oparte o protokoły internetowe (tzn. rodziny TCP/IP), w poniższym tekście ograniczymy się do tychże protokołów.
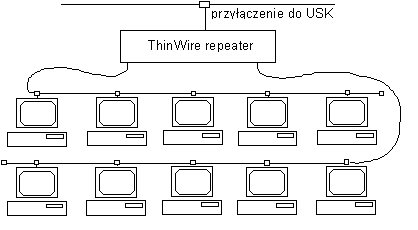
Rys. 1. Sieć lokalna oparta o ThinWire Ethernet.
Przyłączenie komputera do sieci wymaga zatem wyposażenia go w kartę (adapter) Ethernet. Na rynku dostępne są obecnie karty wielu producentów, ze względu jednak na niezawodność i kompatybilność preferowane są karty firm 3Com (3C503, 3C509) i SMC (Elite, Ultra). Dokonując zakupu karty należy zwrocić uwagę na typ okablowania, do jakiego karta ma być przyłączona - większość kart dostępna jest w 2 osobnych wersjach dla okablowania ThinWire i Twisted Pair. Niektórzy producenci oferują też tzw. Combo - karty wyposażone w obydwa typy styku.
Okablowanie typu ThinWire, aktualnie dominujące w sieci uczelnianej, opiera się o kable koncentryczne 50 i złącza BNC. W okablowaniu takim wykorzystana jest struktura magistrali, tzn. do jednego segmentu kabla można przyłączyć równolegle do 30 komputerów. Przyłączenie wykonuje się z użyciem specjalnych trójników BNC, lub za pomoca gniazd ściennych i kabli pośredniczących (to drugie rozwiązanie, choć bardziej estetyczne, jest droższe i tym samym podważa sens użycia okablowania ThinWire, którego główną zaleta jest niska cena). Połączenie segmentu kabla (lub kilku segmentów) z kablem głównym sieci uczelnianej (ThickWire Ethernet) następuje poprzez ThickWire/ThinWire repeater i ThickWire transceiver. Jak z tego wynika, jeden repeater moze zapewnić podłaczenie do sieci uczelnianej dla 30 (a w przypadku użycia repeatera wieloportowego n*30, gdzie n typowo wynosi 4 lub 8) komputerów - w praktyce dla całej sieci lokalnej.

Rys. 2. Sieć lokalna oparta o Twisted Pair Ethernet
Okablowanie Twisted Pair (TP), jak sama nazwa wskazuje, wykorzystuje skrętkę (kabel typu telefonicznego) i złącza RJ45. W rozwiązaniu tym do każdego podłączonego komputera prowadzony jest indywidualny kabel od repeatera (w przypadku Twisted Pair określanego też czasem jako TP hub). Ponieważ typowe repeatery TP mają 8, 12 lub 16 gniazd, niezbędny jest zakup jednego repeatera na każde n (8,12,16) komputerów, co w wiekszości jednostek organizacyjnych AGH oznacza 2-3 repeatery. Ponadto gwieździsta struktura okablowania wymaga większych ilości kabla. Te czynniki powodują, że sieć oparta o TP jest bardziej kosztowna w budowie od ThinWire. Wyższy koszt równoważą jednak liczne zalety TP:
1. Łatwość wprowadzania zmian. Np. przesunięcie komputera do innego pomieszczenia wymaga tylko przeciagnięcia tam kabla. Nie odbija się to na pracy innych użytkowników sieci. W rozwiązaniu opartym o ThinWire wprowadzenie jakichkolwiek zmian w okablowaniu wymaga rozłączenia (przerwania pracy) całego segmentu kabla.
2. Większa niezawodność. Ewentualne uszkodzenie jednego z komputerów (czy też prowadzącego do niego kabla, złącza itd.) nie przeszkadza w pracy innym użytkownikom.
3. Łatwość izolowania usterek. W przypadku ThinWire, uszkodzenie jednego złącza może zaburzyć pracę całego segmentu sieci. Znalezienie wadliwego złącza może okazać się niezwykle czasochłonne (spędziłem kiedyś 2 dni szukając takiego uszkodzenia w laboratorium złożonym z 40 komputerów). W przypadku TP, uszkodzenie jednego złącza zaburza pracę dokładnie jednego komputera, znalezienie usterki jest więc znacznie łatwiejsze.
4. Perspektywy rozwoju. Już obecnie dostępne są na rynku (choć niezbyt rozpowszechnione i drogie) produkty sieciowe mogące w przyszłosci wyprzeć z użycia Ethernet: FDDI, tzw. Fast Ethernet i ATM. Produkty te umożliwiają wykorzystanie istniejącego okablowania TP do transmisji z szybkościami o wiele większymi (10-15 razy) niż obecnie stosowany standard Ethernet. Nic nie jest mi wiadome o analogicznych rozwiązaniach dla okablowania ThinWire.
Jak wynika z powyższego zestawienia, o ile nie jest to konieczne z powodów finansowych, w nowych instalacjach sieciowych należy preferować rozwiązania oparte o Twisted Pair.
Jeżeli planujemy podłączenie nowego komputera do już istniejącej sieci lokalnej, z konieczności należy zakupić kartę odpowiednią do istniejącego już typu okablowania. Zakup taki należy skonsultować z administratorem sieci lokalnej w jednostce organizacyjnej. Nieco bardziej skomplikowana jest sytuacja w przypadku komputerów innych niż PC (stacje robocze i servery Unixowe) - maszyny takie z reguły oferowane są z wbudowanym adapterem Ethernet. Przy zakupie należy porozumieć się z dostawcą odnośnie możliwości podłączenia do istniejącego okablowania.
Podłączenie komputera do sieci powinno być przeprowadzone przez administratora sieci lokalnej lub osobę przez niego upoważnioną. Należy tu ostrzec potencjalnych majsterklepków, że samodzielne, nieautoryzowane manipulacje przy okablowaniu sieciowym mogą poważnie zakłócić funkcjonowanie sieci i w związku z tym są explicite zabronione w Regulaminie USK.
Przyczyną wielu przykrych niespodzianek bywa fakt, że karta Ethernet, podobnie jak wiele innych interfejsów w IBM PC, wymaga przydzielenia numeru przerwania i adresu w przestrzeni wejścia/wejścia komputera (nierzadko także w przestrzeni adresowej pamięci). Czasami, na skutek błędnej konfiguracji, któryś z tych parametrów karty może pokrywać się z już wcześniej przydzielonym innemu urządzeniu (np. karcie RS-232, drukarce, skanerowi...), co uniemożliwia pracę karty, lub co gorsza - w sposób niedeterministyczny zakłóca pracę obydwu urządzeń. W takich wypadkach niezbędne jest zasięgnięcie rady eksperta - w pierwszym rzędzie lokalnego administratora i/lub osoby instalującej kartę.
Odrębnym zagadnieniem jest możliwość używania protokołów TCP/IP równolegle z np. Novell Netware (protokół IPX). Możliwe są dwa rozwiązania tego problemu, przedstawione na schematach poniżej. Pierwsze polego na "skłonieniu" Novella do korzystania z pośrednictwa drivera pakietowego - używa się w tym celu programu IPXTCP zamiast standardowego (dostarczonego przez Novella) drivera IPX.COM. Drugie polega na użyciu rozpowszechnianego przez Novella zestawu driverów ODI i programu ODIPKT emulującego driver pakietowy z użyciem drivera ODI.

Rys. 3. Równoległa praca Netware i TCP/IP
Jak wspomniano wyżej niektóre programy implementują protokoły TCP/IP wewnętrznie i do swej pracy wymagają tylko drivera pakietowego lub odpowiednio ODIPKT. Inne wymagają drivera TCP/IP (pracującego nad driverem pakietowym lub niezależnie, z użyciem własnego drivera). Przykładem programu pracującego z driverem pakietowym jest omawiany dalej CUTCP/CUTE.
Adres IP jest liczbą 32-bitową. Ponieważ liczby tej długosci są trudne do zapamiętania i posługiwania się, tradycyjnie zapisuje się adresy IP jako grupy czterech liczb 8-bitowych, zapisanych dziesiętnie i oddzielonych kropkami, np. 149.156.96.9. Aby jeszcze dalej uprościć pracę użytkownikom sieci, stosuje się tzw. adresy (nazwy) symboliczne, które są automatycznie tłumaczone na adresy IP w postaci numerycznej przez oprogramowanie sieciowe - np. adres symboliczny galaxy.uci.agh.edu.pl tłumaczy się na podany w poprzednim zdaniu adres numeryczny. Adresy symboliczne typowo odzwierciedlają strukture logiczną sieci Internet - np. galaxy.uci.agh.edu.pl należy interpretować jako: komputer o nazwie galaxy, znajdujący się w uci będącym częścią agh, które jest instytucją edukacyjną w Polsce (tradycyjnie do zapisu nazw symbolicznych używa się tylko małych liter). Kolejne człony nazwy symbolicznej noszą nazwę domen - tak więc np. całą Polskę obejmuje domena pl.
O ile posiadanie adresu numerycznego jest konieczne do pracy z protokołami TCP/IP, o tyle adres symboliczny stanowi tylko wygodne uproszczenie i nie jest niezbędny (poza bardzo specyficznymi sytuacjami). Przydział adresów (zarówno numerycznych jak i symbolicznych) jest zorganizowany hierarchicznie: centralny, ogólnoświatowy zespół koordynacyjny Internetu (aktualnie o nazwie Internet Network Information Center) przydziela bloki adresow poszczególnym centralom krajowym (w przypadku Polski - sieci NASK), te z kolei - instytucjom, które wewnętrznie mogą stosować dalszą hierarchię. Tak też jest w przypadku AGH: cała uczelnia dysponuje blokiem adresów od 149.156.96.0 do 149.156.127.255 i domeną agh.edu.pl. Administrator USK może przydzielać podbloki (tzw. podsieci IP) oraz domeny niższego poziomu (subdomeny) administratorom sieci lokalnych w jednostkach organizacyjnych AGH - np. Wydział Fizyki i Techniki Jądrowej dysponuje podsiecią 149.156.110.xxx i domeną ftj.agh.edu.pl. Administrator sieci lokalnej z kolei przypisuje adresy w ramach swojej podsieci IP i nazwy w ramach swojej domeny. Wbrew rozpowszechnionemu mniemaniu, adresy numeryczne nie mają większego związku z położeniem geograficznym - np. blok adresów bezpośrednio przylegający do bloku adresów przydzielonego instytucji w Polsce może należeć do instytucji w USA lub zgoła na Tajwanie; bloki te są przydzielane kolejno w miarę zgłoszeń.
Należy zwrócić uwagę, że unikalność adresów IP jest koniecznym warunkiem poprawnej pracy sieci. Na każdym komputerze przyłączonym do sieci Internet wolno korzystać wyłącznie z adresu przydzielonego temu komputerowi przez administratora sieci - w przeciwnym razie istnieje ryzyko użycia adresu już wykorzystywanego przez inny komputer, co prowadzi do błędnego funkcjonowania i w konsekwencji "zawieszenia" obydwu.
Dla większości usług sieci Internet oprogramowanie typu "server" dostępne jest pod systemem Unix (czasami też pod innymi systemami wielodostępnymi, jak VM, VMS itd.; pod MS-DOS rzadziej). Oprogramowanie typu "klient" natomiast jest zazwyczaj dostępne dla wielu platform sprzętowo-systemowych, włącznie z komputerami PC pracującymi pod systemem MS-DOS. Poniżej omówione zostały najbardziej popularne usługi sieciowe oparte o tę ideę, przy czym tam, gdzie było to możliwe, została opisana zarówno Unixowa, jak i MS-DOSowa wersja oprogramowania "klient". Warto zaznaczyć, że o ile wersje Unixowe są bardziej popularne i zazwyczaj lepiej dopracowane, dla wielu użytkowników zupełnie wystarczające mogą okazać się wersje MS-DOSowe, których dodatkową zaletą jest to, że nie wymagają od użytkownika posiadania konta Unixowego (dotyczy to m.in. usług takich jak FTP, Gopher, WWW, IRC, USENET News).
Bliższe informacje o programach w systemie Unix można zazwyczaj uzyskać z użyciem komendy man (od manual - podręcznik); np. komenda man telnet udzieli szczegółowych informacji o komendzie telnet.
Procedura przyznawania konta zależy również od administratorów danego systemu - np. w ACK "Cyfronet" (systemy Sun i Convex) konta mogą otrzymywać wyłącznie pracownicy uczelni na podstawie odpowiedniego formularza (do otrzymania w sekretariacie UCI). W UCI konta mogą otrzymać pracownicy AGH (na podstawie pisma z pieczątką katedry) oraz studenci AGH (na podstawie formularza potwierdzonego przez prowadzącego zajęcia lub przez dziekanat wydziału; formularze te można otrzymać od operatorów w UCI, p. 416). Komputer przeznaczony do użytku pracowniczego nosi nazwę galaxy (jest to Sun SPARCserver 690MP), do użytku studentów UCI dysponuje komputerami Unixowymi: student (Sun SPARCserver 10/40, system operacyjny SunOS 4.1.3), kubus (PC/486, system operacyjny SCO Unix) i krakds (DEC DECsystem 5100, system operacyjny Ultrix 4.2). Dokładniejsze informacje o tych komputerach można uzyskać w UCI.
Do zdalnej pracy interakcyjnej służą wśród protokołów rodziny TCP/IP Telnet i Rlogin. Telnet jest protokołem starszym i bardziej rozpowszechnionym - istnieje wiele pakietów zarówno komercyjnych jak i Public Domain realizujących ten protokół. Między innymi, Telnet wchodzi w skład komercyjnych pakietów PC NFS (firmy Sun) i PC TCP (firmy FTP Software). W USK najbardziej rozpowszechniony jest niekomercyjny (darmowy dla użytkowników akademickich) pakiet CUTCP/CUTE (Clarkson University TCP/Clarkson University Terminal Emulator). Pakiet ten zawiera program telbin implementujący zarówno protokół Telnet jak i Rlogin. Program telbin zawiera wewnętrznie zaimplementowany protokół TCP/IP, do pracy wymaga więc tylko drivera pakietowego. Wszelkie informacje konfiguracyjne dla programu (i innych programów pakietu CUTCP) znajdują sie w pliku wskazywanym przez zmienną środowiskową systemu MS-DOS o nazwie CONFIGTEL. Tak więc np. aby użyć zbioru c:/cutcp/uci.tel jako zbioru konfiguracyjnego dla CUTCP, należy wykonać (np. umieścić w AUTOEXEC.BAT) komendę:
set CONFIGTEL=c:/cutcp/uci.tel
W zbiorze tym znajduje się m.in. informacja o adresie IP komputera, na którym program uruchamiamy, oraz adres najbliższego routera USK, a zatem należy zmodyfikować ten zbiór na każdym komputerze, na jakim program będzie uruchamiany. Wraz z oryginalną dystrybucją pakietu (dostępna w UCI) rozpowszechniany jest przykładowy zbiór konfiguracyjny CONFIG.TEL zawierający komentarze wyjaśniające znaczenie wszystkich opcji konfiguracyjnych obecnych w pliku.
Uruchomienie programu może się odbyć na 2 sposoby: można wywołać program telbin z parametrem, którym jest adres maszyny w sieci - wówczas od razu następuje połączenie z tą maszyną; można też wywołać program bezparametrowo - wówczas w celu otwarcia sesji z maszyną Unixową trzeba nacisnąć kombinację Alt-A - powoduje to wyświetlenie promptu Telnet>, na co należy odpowiedzieć wpisaniem adresu. Odpowiednio użycie kombinacji Alt-Z wyświetla prompt Rlogin> - odpowiada się również podaniem adresu maszyny, lecz sesja zostanie nawiązana z użyciem protokołu Rlogin, a nie Telnet (z punktu widzenia przeciętnego użytkownika nie ma to wiekszego znaczenia). Możliwe jest podanie dodatkowych opcji w wywołaniu programu - najważniejszą z nich jest chyba opcja -e, która pozwala na przedefiniowanie dowolnych definicji ze zbioru konfiguracyjnego.
Po nawiązaniu sesji system Unix zgłasza się komunikatem zależnym od konkretnej instalacji - typowo brzmi on np.:
Unix System V Release 4
login:
Reakcją na napis login: powinno być podanie identyfikatora użytkownika. System zapyta wówczas o hasło (podczas pisania hasło nie pokazuje się na ekranie!). Dalsze postępowanie (jak również reakcja systemu na błędne hasło) zależy od konkretnej instalacji systemu Unix - w razie problemów należy skonsultować się z administratorem konkretnej maszyny.
CUTCP pozwala użytkownikowi nawiązać kilka równoczesnych sesji (z tą samą lub z różnymi maszynami) - wystarczy po nawiązaniu pierwszego połączenia nacisnąć ponownie Alt-A, podać adres maszyny, itd. Każdej sesji zostaje przydzielony wirtualny ekran - przełączanie pomiędzy nimi odbywa się z użyciem klawiszy Alt-L i Alt-N. Zamknięcie wszystkich sesji (poprzez wydanie komendy Unixa logout lub odpowiednika) spowoduje zakończenie pracy programu. Należy pamiętać o zakończeniu pracy z Unixem przed wyłączeniem komputera - wyłączanie lub resetowanie komputera w trakcie sesji z Unixem może spowodować niepożądane efekty (np. "widmowe" sesje - inni użytkownicy mają wrażenie, że dany użytkownik nadal pracuje).
Dodatkowe szczegóły na temat pakietu CUTCP znajdują się w rozdziale poświęconym FTP.
Rzecz jasna, możliwe jest również nawiązanie połączenia protokołem Telnet lub Rlogin pomiędzy dwiema maszynami Unixowymi, tzn. pracując pod systemem Unix mozna połączyć się z inną maszyną Unixową wydając komendę telnet lub odpowiednio rlogin. Przykład:
telnet galaxy.uci.agh.edu.pl spowoduje nawiązanie połączenia z komputerem galaxy.
Jedyną istotną z punktu widzenia użytkownika różnicą pomiędzy protokołami Telnet i Rlogin jest możliwość uproszczonej autentykacji w protokole Rlogin. Zazwyczaj protokół Rlogin podobnie jak Telnet wymaga podania identyfikatora i hasła użytkownika. Jeżeli jednak znany jest lokalny (tzn. na maszynie, z której nawiązujemy połączenie) identyfikator użytkownika, to zakłada się, że identyfikator użytkownika na maszynie docelowej ma być taki sam, i zadawane jest od razu pytanie o hasło. Rzecz jasna w przypadku lokalnej maszyny Unixowej identyfikator użytkownika jest znany; natomiast w przypadku PC z pakietem CUTCP identyfikator lokalny może być podany w pliku konfiguracyjnym CUTCP lub z użyciem opcji programu telbin, np. telbin -e "myname=szymon" odniesie skutek taki sam jak wpisanie myname=szymon do zbioru konfiguracyjnego, a rezultatem tej operacji będzie ustawienie identyfikatora lokalnego na szymon, i w rezultacie operacja Rlogin (Alt-Z) będzie jedynie wymagała podania hasła na docelowej maszynie. Dodatkowo, jeżeli adres maszyny lokalnej występuje w zbiorze .rhosts w katalogu danego użytkownika na docelowej maszynie, pytanie o hasło również nie zostanie zadane! O tej możliwości wspominamy tu raczej dla przestrogi niż dla porady - stosowanie jej bowiem pociąga za sobą niebezpieczeństwo dostępu do konta przez osoby postronne; dlatego też większość administratorów systemów Unixowych odradza lub wręcz zabrania używania pliku .rhosts - UCI nie jest tu wyjątkiem.
Do używania X Windows stworzono specjalne terminale graficzne - tzw. X-terminale - zawierające wbudowaną kartę Ethernetu, oprogramowanie komunikacyjne TCP/IP i oprogramowanie X Windows. Ich cena jest relatywnie wysoka (800-3000 USD) i stąd duża popularność rozwiązań programowych, emulujących X-terminal w oparciu o komputer kompatybilny z IBM PC. Z reguły minimalnymi wymaganiami sprzętowymi takich programów są: procesor 386, 4MB RAM, karta grafiki SVGA, mysz i oczywiście karta Ethernet. Dodatkowo, niektóre z nich wymagają oprogramowania implementującego TCP/IP i/lub Microsoft Windows jako środowiska operacyjnego; inne zadowalają się systemem MS-DOS i driverem pakietowym. Podanie dokładnej instrukcji posługiwania się takimi pakietami nie jest możliwe ze względu na wielość dostępnych na rynku rozwiązań (Uwaga: w chwili pisania tego tekstu, nie było mi znane żadne oprogramowanie niekomercyjne tego rodzaju).
Należy zaznaczyć, że korzystanie z X Windows wymaga posiadania konta na komputerze z systemem Unix, wyposażonym w odpowiednie oprogramowanie. Rzecz jasna, rozpoczęcie pracy w systemie X Windows wymaga autentykacji tzn. potwierdzenia tożsamości użytkownika, tak samo jak ma to miejsce w przypadku protokołów Telnet i Rlogin. Stosowanych jest tu kilka rozwiązań, z których niektóre (przypominające koncepcyjnie wspomnianą przy okazji protokołu Rlogin autentykację uproszczoną) są zbyt niebezpieczne, aby można było je polecać. Właściwą metodą autentykacji użytkowników w systemie X Windows jest zainstalowanie na maszynie Unixowej, z którą mają być otwierane sesje X Windows, specjalnego programu XDM (X Display Manager) stanowiącego część dystrybucji pakietu X Windows. W UCI XDM zainstalowany jest na komputerach galaxy i student. Program ten po nawiązaniu połączenia wymaga podania identyfikatora użytkownika i jego hasła, podobnie jak ma to miejsce w przypadku protokołu Telnet.
Pożyteczną cechą systemu X Windows jest możliwość równoczesnego korzystania z programów uruchomionych na różnych maszynach w sieci. O ile komunikacja z maszyną, na której rozpoczęto sesję X Windows, nie wymaga żadnych dodatkowych zabiegów, o tyle w przypadku innych maszyn niezbędne jest po pierwsze poinformowanie programów tam uruchamianych, gdzie ma być prowadzone wyświetlanie, po drugie, poinformowanie X servera, że powinien obsługiwać te żądania wyświetlania. Tę pierwszą czynność wykonujemy nadając na maszynie "zdalnej" wartość zmiennej środowiskowej Unixa o nazwie DISPLAY. Wartościa tą powinno być xxx:0, przy czym xxx reprezentuje adres naszego komputera lokalnego (tzn. komputera, na którym pracuje X server, innymi słowy - komputera z graficznym ekranem; jak łatwo z tego wywnioskować, X-terminal również posiadać musi swój adres IP!). Sposób nadania wartości zmiennej zależy od używanego tzw. shella, czyli interpretera poleceń Unixa. W csh i jego odmianach należy użyć komendy setenv DISPLAY 149.156.96.8:0 (podany adres proszę oczywiście zastąpić własnym!). W przypadku sh i jego odmian należy napisać: DISPLAY=149.156.96.8:0; export DISPLAY. Jeżeli teraz spróbujemy uruchomić program graficzny, będzie on usiłował wyświetlić swoje okienko/okienka na ekranie komputera o tym adresie. Żeby ta operacja się powiodła, trzeba jeszcze poinformować ten komputer (a dokładnie, X server), że wyrażamy na to zgodę - w przeciwnym razie każdy użytkownik sieci mógłby wyświetlać dowolne okienka na naszym ekranie... Można to zrobić na kilka sposobów:
1. Zezwolić wszystkim komputerom w sieci na dostęp do naszego ekranu; po uruchomieniu konkretnego programu graficznego zezwolenie to cofnąć. Służą do tego odpowiednio komendy xhost + i xhost -.
2. Jeżeli przewidujemy potrzebę czestszego uruchamiania programów na danym komputerze zdalnym, możemy selektywnie zezwolić temu komputerowi na dostęp do naszego ekranu z użyciem komendy xhost +adres, gdzie adres jest adresem tegoż komputera zdalnego. Komenda xhost -adres odnosi skutek odwrotny, tzn. cofa zgodę na dostęp do ekranu dla tego komputera zdalnego.
3. Powyższe 2 metody mają istotną wadę: nie pozwalają naprawdę dokładnie ograniczyć dostępu do naszego ekranu, nie rozróżniają bowiem pomiędzy różnymi użytkownikami zdalnego komputera (wszyscy użytkownicy komputera zdalnego albo równocześnie mają, albo nie mają prawa do wyświetlania na naszym ekranie). Skuteczną metodą rozróżnienia jest użycie klucza kodowego, generowanego przez komputer lokalny, a następnie przesyłanego na konto danego użytkownika na maszynie zdalnej, tak, że tylko programy tego uzytkownika mają dostęp do klucza. Służy do tego program xauth - niestety metoda ta nie ma zastosowania w przypadku większości znanych mi X-terminali i programów emulacyjnych, dlatego nie podajemy szczegółów; można je znaleźć w opisie programu xauth.
Na koniec należy wspomnieć, że system X Windows daje użytkownikowi niezwykle szerokie możliwości konfiguracyjne. Dwa główne zbiory umożliwiające konfiguracje X Windows w naszej instalacji (tzn. w UCI) to .Xsession i .Xdefaults. Ten pierwszy zawiera komendy, jakie należy wykonać przy starcie X Windows - m.in. polecenia uruchamiające poszczególne programy, z których standardowo chcielibyśmy korzystać. Ten drugi zawiera definicje tzw. zasobów (resources), czyli pewnych wartości traktowanych przez rozmaite programy pracujące pod kontrolą X Windows jako opcje konfiguracyjne. Dokładniejsze objaśnienie filozofii zasobów można znaleźć w literaturze.
Ponieważ FTP jest kolejnym przykładem realizacji idei klient-server, do skorzystania z tej usługi jest niezbędne, aby na komputerze, do/z którego chcemy przesłać zbiór, działał server FTP - ten warunek jest spełniony dla prawie wszystkich systemów Unixowych. Na komputerze, z którego chcemy zainicjować transmisję, musi być dostępne oprogramowanie "klient". Pod Unixem, jest on zwykle dostępne pod postacią programu ftp, jakkolwiek istnieją też rózne wersje udoskonalone, np. ncftp. Nawiązanie połączenia FTP polega na wywołaniu programu z parametrem - adresem maszyny, z którą chcemy nawiązać połączenie, np. ftp lajkonik.cyf-kr.edu.pl albo ftp 149.156.96.9. Program zada wówczas pytanie o identyfikator, a następnie hasło użytkownika na maszynie, z którą nawiązujemy połączenie. Jeżeli zostaną podane niepoprawnie, pojawie się komunikat "Login failed", w przeciwnym razie "User logged in". Od tego momentu program ftp prowadzi dialog z użytkownikiem, akceptując komendy, aż do wydania komendy kończącej pracę programu i powodującej powrót do systemu operacyjnego. Oto zwięzły opis podstawowych komend programu:
dir - sprawdzenie zawartości katalogu
cd katalog - zmiana katalogu
bin - wybranie binarnego trybu transmisji
asc - wybranie tekstowego trybu transmisji
get nazwa - pobranie zbioru
put nazwa - umieszczenie zbioru
bye - zakończenie połączenia.
Tak więc, aby np. przesłać zbiór o nazwie proba.txt na swoje konto na komputerze lfs.cyf-kr.edu.pl, gdzie moim identyfikatorem jest gusokol, powinienem wykonać następujące operacje:
1. Wydać komendę ftp lfs.cyf-kr.edu.pl
2. Na pytanie Username: odpowiedzieć gusokol, następnie na pytanie Password: podać swoje hasło na maszynie lfs.cyf-kr.edu.pl
3. Po ukazaniu się promptu ftp> wydać komendę put proba.txt
4. Po zakończeniu transmisji zbioru i pojawieniu się ponownie promptu wydać komendę bye, aby zakończyć połączenie.
Komenda get jest przeciwieństwem put, tzn. służy do transmisji zbiorów z komputera zdalnego na lokalny.
Należy zwrócić uwagę, że w trybie tekstowym należy transmitować wyłącznie zbiory tekstowe - wszystkie inne (jak np. programy wykonywalne, archiwa typu .zip, .tar itd., grafika w dowolnym formacie) muszą być przesłane w trybie binarnym, a zatem przed wydaniem komendy put lub get należy użyć komendy bin dla przełączenia typu transmisji - w przeciwnym razie zbiory zostaną przesłane niepoprawnie.
Pomiędzy dwoma systemami Unix z reguły można przesyłać wszystkie zbiory w trybie binarnym. Ponadto, program ncftp (w odróżnieniu od ftp) automatycznie wybiera właściwy tryb transmisji zależnie od zawartości zbioru.
Pod systemem MS-DOS oprogramowanie FTP jest dostępne w ramach rozmaitych pakietów - m.in. omawiany już uprzednio pakiet CUTCP zawiera program ftpbin, będący implementacją klienta FTP. Posługiwanie się tym programem jest analogiczne do posługiwania się komendą ftp w systemie Unix. Podobnie jak program telbin, ftpbin czerpie informacje konfiguracyjne ze zbioru, wskazanego przez zmienną środowiskową CONFIGTEL.
Jednym z bardziej typowych zastosowań protokołu FTP w warunkach USK jest przesyłanie zbiorów pomiędzy komputerem Unixowym, na którym użytkownik ma konto, a komputerem PC na biurku użytkownika. Ponieważ zazwyczaj potrzeba taka pojawia się w czasie zdalnej pracy z Unixem, stosunkowo niewygodne byłoby przerywanie pracy, powrót do systemu MS-DOS, uruchamianie programu np. ftpbin, i powrót do programu telbin. Co za tym idzie, telbin oferuje użytkownikowi cenną możliwość: implementuje on server FTP, z którym można nawiązać połączenie z innej maszyny, w tym z maszyny Unixowej, na której użytkownik właśnie pracuje (z użyciem tegoż programu telbin). Oczywiście, w celu ochrony przed dostępem via FTP do naszego komputera przez osoby postronne, można (w specjalnym pliku) zdefiniować hasła dostępu dla poszczególnych użytkowników komputera. Na ogół jednak, zadowalającym rozwiązaniem jest wyłączenie tej opcji i korzystanie wyłącznie z tzw. wewnętrznego hasła (internal password) programu telbin. W praktyce wygląda to tak, że po wydaniu (pod Unixem, w ramach sesji proawdzonej z użyciem programu telbin) komendy ftp adres, gdzie adres odnosi się do komputera, przy którym siedzimy, pojawia się pytanie o identyfikator użytkownika, na które odpowiadamy dowolnie - a w odpowiedzi na pytanie o hasło naciskamy kombinację klawiszy Alt-W. Użycie tej kombinacji powoduje wygenerowanie przez telbin losowego ciągu cyfr, które zostają przesłane jako hasło. Server FTP, stanowiący przeciez część tego samego programu telbin, "wie" jaki ciąg cyfr jest poprawnym hasłem, i zaakceptuje to właśnie żądanie połączenia, zaś odrzuci wszystkie inne, pochodzące od postronnych użytkowników sieci. Dla dalszego ułatwienia pracy, kombinacja klawiszy Alt-T w programie telbin powoduje wpisanie komendy ftp z parametrem będącym adresem IP komputera, na którym pracuje telbin. Tak więc do nawiązania połączenia FTP między komputerem Unixowym a komputerem PC, którego używamy właśnie jako terminala, wystarczy nacisnąć kolejno: Alt-T, Enter, Alt-W. Dalsza praca wygląda tak jak zwykle - akceptowane są dowolne komendy FTP aż do wydania komendy bye lub odpowiednika (komenda quit lub kombinacja Ctrl-D są synonimami dla bye). Należy jednak zaznaczyć, że w tym układzie kierunki transmisji są sprzeczne z intuicją użytkownika: ponieważ z punktu widzenia FTP get oznacza pobranie pliku z servera do klienta, a komputer PC jest w tym przypadku serverem, nie klientem, przesłanie pliku z PC do Unixa wymaga użycia komendy get, a z Unixa do PC - put (odwrotnie niż w przypadku użycia programu ftpbin czy innego klienta FTP pod MS-DOS).
Nieco bardziej szczegółowego omówienia wymaga wspomniana wyżej koncepcja anonymous FTP. Umożliwia ona użytkownikom sieci Internet pobieranie (czasami też umieszczanie) zbiorów w wydzielonych katalogach pewnych serverów FTP (typowo prowadzonych przez uniwersytety lub duże firmy), bez posiadania przez użytkownika konta na tych komputerach. Zamiast własnego identyfikatora, w celu uzyskania dostępu do takiego servera używa się identyfikatora ftp lub anonymous. Nazwa anonymous jest nieco myląca - dostęp nie jest stuprocentowo anonimowy; server wymaga podania jako hasła adresu poczty elektronicznej osoby korzystającej z servera, jednak nie wszystkie servery weryfikują adres podany przez użytkownika; słuzy on wyłącznie do celów statystycznych. Większość serverów anonymous FTP ma pewne dodatkowe restrykcje, np. dostęp do nich jest dozwolony tylko poza godzinami szczytu lub ograniczona jest liczba użytkowników mogących korzystać z servera równocześnie. Bezpośrednio po nawiązaniu połączenia, servery takie zazwyczaj udzielają informacji o restrykcjach. Stosowanie się do nich jest nie tylko grzecznością ze strony użytkownika sieci wobec administratorów servera udostępniającego za darmo swoje zbiory - często jest także niezbędnym warunkiem kontynuowania przez nich działalności; miały już miejsce przypadki likwidacji interesujących serverów anonymous FTP z powodu notorycznego nadużywania ich przez użytkowników.
Niektóre szczególnie popularne zasoby (programy, dokumenty, itd.) są przechowywane na wielu serverach anonymous FTP na świecie. Zanim zaczniesz ściagać nierzadko wielkie ilości danych z servera położonego na drugim końcu świata, upewnij się, czy te same zbiory nie są dostępne bliżej: w Europie, w Polsce, a może nawet w Krakowie... Obecnie w Krakowie funkcjonują dwa duże servery anonymous FTP, udostępniające ponad 1000MB zbiorów kazdy: ftp.uci.agh.edu.pl w Uczelnianym Centrum Informatyki AGH i ftp.cyf-kr.edu.pl w ACK "Cyfronet". W rzeczywistości, podane adresy są alternatywnymi adresami komputerów galaxy.uci.agh.edu.pl i lajkonik.cyf-kr.edu.pl. Zalecane jest jednak używanie tych właśnie adresów alternatywnych, które na pewno zachowają ważność, nawet jeśli usługa zostanie przeniesiona na inny komputer - nazwa alternatywna również zostanie wówczas przeniesiona.
Wyszukiwanie interesujących zbiorów na serverach FTP może okazać się czynnościa podobną do szukania igły w stogu siana... Jezeli znamy przynajmniej nazwę lub część nazwy interesującego zbioru, pomocą może służyć omówiony poniżej system Archie. W przeciwnym razie, prawdopodobnie wygodniej będzie prowadzić poszukiwania z pomocą usług bardziej nowoczesnych niż FTP, takich jak Gopher i WWW. Ponadto, informacje o wielu nowych programach (i ich lokalizacji na serverach FTP) można uzyskać przez lekturę odpowiednich list dyskusyjnych i grup dyskusyjnych USENET News poświęconych nowościom w oprogramowaniu (np. comp.archives.msdos.announce).
Pod Unixem, klient systemu Archie nosi zazwyczaj nazwę archie (nie jest częścią dystrybucji standardowych systemów Unix - musi być doinstalowany przez administratora). Rozmaite opcje pozwalają na dokładniejsze sterowanie procesem wyszukiwania. Przykład:
archie -m 10 -s win - szukaj wszystkich zbiorów, których nazwa zawiera napis win wypisując pierwszych 10 odpowiedzi (Uwaga: nie należy formułować zbyt ogólnych pytań; pytanie powyższe, gdyby nie ograniczono ilości żądanych odpowiedzi do 10, mogłoby udzielić informacji o dosłownie tysiącach różnych zbiorów zawierających napis win w nazwie, z których 99% jest kompletnie nieinteresujących dla użytkownika zadającego pytanie).
archie -c vbrun200.zip -h archie.univie.ac.at - korzystając z serwera Archie na Uniwersytecie Wiedeńskim (jest on położony najbliżej Polski), szukaj zbioru vbrun200.zip
archie -l - wypisz listę znanych serwerów Archie.
Istnieje obecnie co najmniej jedna wersja klienta Archie dla systemu MS-DOS, ale wersja ta jest na tyle niedopracowana, że nie polecam jej używania. Należy się spodziewać, że w miarę zastępowania anonymous FTP przez wygodniejsze dla użytkowników formy dostępu do informacji (takie jak Gopher i WWW) Archie straci na znaczeniu na rzecz bardziej uniwersalnych systemów wyszukiwania informacji.
Przykłady:
finger - kto (i od jak dawna) jest zalogowany na lokalnej maszynie
finger @lfs.cyf-kr.edu.pl - kto jest zalogowany na maszynie o danym adresie
finger kowalski - informacja o użytkowniku kowalski na lokalnej maszynie (jak brzmi jego pełne nazwisko, kiedy po raz ostani korzystał z konta itd.)
finger smith@src.doc.ic.ac.uk - ta sama informacja o użytkowniku na maszynie o danym adresie. Znak @ oddzielający tu identyfikator od adresu maszyny należy czytać (podobnie jak w adresach poczty elektronicznej) jako angielski przyimek at (na, przy).
Należy zauważyć, że zamiast identyfikatora użytkownika można tu użyć jego nazwiska - w ten sposób można dowiedzieć się, jakiego identyfikatora używa dana osoba. Uwaga: na niektórych komputerach usługa ta może być niedostępna.
Jak dotąd, nie jest mi znana żadna zadowalająca implementacja klienta protokolu Finger dla MS-DOS.
W rozmaitych wersjach systemu Unix bywają dostępne inne komendy umożliwiające uzyskiwanie informacji o uzytkownikach na tym komputerze - do najbardziej popularnych należa who, wypisująca kto, od jak dawna i skąd (w sensie sieciowym, tj. adresu IP) pracuje w danej chwili na tym komputerze; oraz whodo lub w, informująca jakie komendy wykonują w danej chwili poszczególni użytkownicy (ta ostatnia komenda w wielu systemach jest niedostępna).
Przykłady z użyciem UCB mail:
mail premier@urm.gov.pl - wyślij list pod dany adres (w tym wypadku: Premiera RP); na pytanie o Subject: należy podać tytuł listu (jedna linia tekstu); list kończy naciśnięcie Ctrl-D na początku nowej linii lub wprowadzenie kropki jako jedynego znaku w linii.
mail - sprawdź swoją pocztę. W trybie przeglądania skrzynki pocztowej dostępne są jednoliterowe podkomendy (z opcjonalnym argumentem):
p numer - czytaj list o danym numerze (ten sam efekt daje wpisanie samego numeru)
d numer - skasuj list o danym numerze
s numer nazwa - list o danym numerze zachowaj w zbiorze o danej nazwie
r numer - odpowiedz na list o podanym numerze
m adres - wyślij list pod dany adres
h - wypisz spis listów
z - przejdź do nowej strony spisu
z- - przejdź do poprzedniej strony spisu
q - wyjdź z programu.
Pominięcie numeru oznacza, że operacja ma być wykonana na ostatnio czytanym liście. Dla komend d i s można podać zakres numerów np. 2-5, lub * co oznacza "wszystko".
Składnia adresów e-mailowych. Typowy adres w poczcie elektronicznej składa sie z: identyfikatora użytkownika, znaku @ , który należy czytać jako angielski przyimek at (na, przy), i adresu maszyny (w postaci symbolicznej), na której użytkownik odbiera pocztę. Np. adresem autora niniejszego tekstu mogłoby być: szymon@galaxy.uci.agh.edu.pl. Istnieją jednak liczne odstępstwa od tej zasady. Wysyłając list do innego użytkownika na tym samym komputerze można użyć samego tylko identyfikatora - bez adresu maszyny. Czasami administratorzy konfigurują oprogramowanie poczty elektronicznej tak, aby zamiast adresu maszyny można było uzywać samej tylko domeny - nie jest to regułą, ale np. tak właśnie funkcjonuje oprogramowanie galaxy; stąd adres podany wyżej jest równoważny szymon@uci.agh.edu.pl. Niektóre systemy poczty elektronicznej używają rzeczywistego nazwiska użytkownika zamiast jego identyfikatora - np. adresem Grzegorza Wójcika z Instytutu Automatyki PW jest: G.Wojcik@ia.pw.edu.pl. Na koniec, możliwe jest wysyłanie za pośrednictwem Internetu listów do innych sieci (takich jak BITNET/EARN, UUCP, amatorska sieć Fidonet, krajowe sieci X.25/X.400 itd.) - często używają one adresów o składni mocno odbiegającej od normalnych reguł Internetowych. Najlepszym poradnikiem przy próbach wysłania listu do takich sieci jest "Inter-network mail guide" Scotta Yanoffa.
Uwaga: poprawność adresu nie jest sprawdzana w chwili wysyłki listu. Jeżeli adres nie był poprawny, może upłynąć do 3 dni (na ogół znacznie krócej), zanim zostanie odesłany do nadawcy z odpowiednią adnotacją o błędzie (tzw. bounce mail). Podobnie zwracane są listy, których nie udało się dostarczyć np. z powodu awarii komputera adresata.
Tradycyjnie, na każdym komputerze zdolnym do przyjmowania poczty powinno istnieć konto postmaster - jest to osoba, do której można zwracać się z pytaniami i uwagami odnośnie poczty elektronicznej w danym systemie.
Listy dyskusyjne. Poczta elektroniczna jest zasadniczo metodą komunikacji dwustronnej. Czasami istnieje potrzeba wielostronnej komunikacji w pewnym gronie. Dopóki liczba zainteresowanych osób nie jest duża, każda z nich może rozsyłać swoje listy do wszystkich pozostałych podając więcej niż jednego adresata przy wysyłce listu (np. mail szymon, aksamit, artur@ii.uj.edu.pl, postmaster@cyf-kr.edu.pl ). W przypadku, gdy grupa liczy sobie kilkaset osób, metoda taka byłaby niepraktyczna. Tworzy się zatem tzw. listy dyskusyjne. Lista dyskusyjna posiada własny adres e-mailowy np. polip@camk.edu.pl. Listy wysyłane na taki adres rozsyłane są automatycznie do wszystkich subskrybentów listy. Metody stawania się subskrybentem są różne dla różnych list - w najbardziej typowym rozwiązaniu, należy skorzystać z adresu listserv.
Przykład:. aby zapisać się do listy net-l@vm.cc.torun.edu.pl, Jan Nowak powinien wysłać pod adres listserv@vm.cc.torun.edu.pl list o treści subscribe net-l Jan Nowak.
Dla niektórych list subskrypcja prowadzona jest ręcznie, tzn. należy wysłać list z prośbą o zapisanie do osoby wskazanej jako "właściciel listy" w spisie list dyskusyjnych (spis polskojęzycznych list dyskusyjnych jest okresowo publikowany w "Pigułkach" - periodyku rozsyłanym za pośrednictwem poczty elektronicznej; a także dostępny przez WWW). Nie jest mile widziane wysyłanie do listy listów typu "Pomóżcie mi się zapisać/wypisać" - jeżeli ktoś nie umie tego sam zrobić, powinien w pierwszej kolejności skontaktować się z postmasterem na własnym komputerze.
Uwaga: użycie komendy r (Reply) dla listu przesłanego przez listę dyskusyjną powoduje zazwyczaj wysłanie odpowiedzi do listy (tzn. do kilku-[-dziesięciu, -set, tysięcy] odbiorców), a nie do autora listu bezpośrednio. Należy mieć to na uwadze, aby uniknąć nieporozumień.
UUENCODE. Pocztą elektroniczną można przesyłać obecnie wyłącznie teksty. Aby przesłać np. program wykonywalny typu .EXE, archiwum typu .ZIP itd. należy najpierw zakodować je do postaci czysto tekstowej z użyciem programu uuencode - program uudecode pozwala rozkodować zbiór do pierwotnej postaci. uuencode/uudecode stanowią standardową część systemu Unix. Nie należy przesyłać poczta dużych zbiorów (powyżej 100KB), gdyż niektóre systemy nie akceptują tak długich listów.
Główne grupy USENETu to:
sci - nauki ścisłe i przyrodnicze
comp - informatyka
soc - zagadnienia społeczno-polityczne i kulturalne
biz - biznes
rec - rekreacja
news - administracja USENETu
alt -inne grupy (przede wszystkim eksperymentalne)
Istnieją również grupy o zasięgu lokalnym np cyfronet czy agh.
Każda z grup głównych ma swoje podgrupy, np. comp.sys czy rec.arts, które z kolei mogą mieć dalsze podgrupy i podpodgrupy np. comp.sys.sun.hardware lub rec.art.books.
Poszczególne grupy funkcjonują na zasadzie list dyskusyjnych, tzn. można wysyłać do nich teksty (nazywane artykułami lub postingami) które następnie rozchodzą się do wszystkich komputerów partycypujących w systemie USENET - służy do tego protokół NNTP (Network News Transfer Protocol). Tu właśnie leży główna różnica pomiędzy USENETem a listami dostępnymi przez e-mail: nie trzeba zostawać subskrybentem grupy USENETu, aby przejrzeć najświeższe (np. z ostatniego tygodnia) postingi do tej grupy. Czas przechowywania artykułów na poszczególnych komputerach jest ograniczony dobrą wolą administratorów i pojemnością dysków - zazwyczaj wynosi od 3 dni do tygodnia.
Uwaga: korzystanie z USENETu dobrze jest rozpocząć od przejrzenia zawartości grupy news.answers, która zawiera wiele artykułów informacyjnych, w tym tzw. FAQ (Frequently Asked Questions) dla poszczególnych grup.
Dostępny jest (poprzez WWW) obszerny artykuł w języku polskim na temat IRC.
Typowy klient IRC pod Unixem to program irc lub ircII. Pod MS-DOSem dostępne są co najmniej 2 wersje: winirc pracujący pod Microsoft Windows i dosirc pracujący w trybie tekstowym (wizualnie przypomina "Trumpet Newsreader" - również jest napisany z użyciem Turbo Vision).
Przykłady:
talk szymon - nawiązanie połączenia z użytkownikiem na tej samej maszynie
talk root@lfs.cyf-kr.edu.pl - nawiązanie połączenia z użytkownikiem BSD Unix
ntalk yymnoga@krak.cyf.kr.edu.pl - nawiązanie połączenia z użytkownikiem System V.
Na ekranie "wołanego" użytkownika pojawiają się komunikaty informujące, kto chce nawiązać z nim rozmowę oraz jaką komendą powinien odpowiedzieć (tzn. talk czy ntalk). Po nawiązaniu połączenia ekran dzielony jest na dwie części: w jednej pojawia się tekst "wysyłany", w drugiej "odbierany". Rozłączenie powoduje zazwyczaj naciśnięcie Ctrl-C przez jednego z rozmówców.
Uwaga: Jeżeli nie udaje się nawiązać połączenia, może to oznaczać jedną z następujących rzeczy:
potencjalny rozmówca ignoruje komunikaty (np. odszedł od terminala);
albo wyłączył ich wyświetlanie komendą mesg n (mesg y przywraca stan zwykły) - jest to odpowiednik odłączenia telefonu;
albo nie jest zalogowany w danej chwili (co można sprawdzić za pomocą Fingera);
albo należało użyć innej komendy (ntalk zamiast talk lub odwrotnie);
albo pomiędzy komputerami rozmówców nie ma połączenia sieciowego (nastąpiła awaria).
Zazwyczaj da się ustalić przyczynę na podstawie komunikatów diagnostycznych.
Serwer Gopher w UCI zawiera m.in. wewnętrzną książkę telefoniczną AGH, tablicę ogłoszeniową, rozmaite publikacje o tematyce sieciowej, archiwa polskich periodyków dostępnych w postaci elektronicznej ("Spojrzenia", "Donosy", "Pigułki" i szereg innych).
Unixowym klientem tej usługi jest program gopher. Może być uruchomiony bezparametrowo (nawiązuje wówczas połączenie z lokalnym serwerem) albo z parametrem będącym adresem serwera z którym należy się połączyć.
Przykład: gopher poniecki.berkeley.edu
Istnieje również program xgopher pracujący w środowisku X Windows. Dla systemu MS-DOS istnieje kilka implementacji klienta Gophera, z których najlepszą chyba jest PC Gopher III (jak zwykle, stworzony z użyciem Turbo Vision).
Gopher jest usługą relatywnie nową (powstał z końcem lat 80-tych w Minnesocie), lecz już obecnie jest wypierany przez bardziej uniwersalną usługę WWW. W tym też kierunku migruje system informacyjny AGH.
zastosowanie idei hypertextu, znanej już wcześniej z systemów pomocy (help) w programach takich jak Microsoft Windows czy Turbo Pascal, do systemu rozproszonego, a następnie rozwinięcie jej do formy hypermediów - połączenia tekstu, grafiki i ew. innych form przekazu (animacja, dźwięk);
zaimplementowanie nowego, efektywnego protokołu przesyłu informacji - HTTP (HyperText Transfer Protocol);
umożliwienie zintegrowania w nowym systemie zasobów już istniejących w innej formie (np. Gophera lub anonymous FTP)
stworzenie jednolitego sposobu adresowania publicznych zasobów sieciowych - tzw. URL (Uniform Resource Locator).
Nagły wzrost popularności WWW nastąpił, gdy w NCSA (National Center for Supercomputer Applications) stworzono nowy program o nazwie Mosaic, będący klientem WWW (a więc integrującym w sobie funkcje klienta HTTP, Gophera, FTP i kilku innych usług) a pracujący w środowisku X Windows. Wkrótce później powstały też wersje programu dla MS Windows i dla Apple MacIntosh. Kolejna wersja rozwojowa Mosaic (opracowana przez firmę Mosaic Communications) nosi nazwę Netscape i jest obecnie sztandarowym klientem WWW (dla X-Windows i MS Windows); istnieją też inne programy: Chimera dla X Windows, Cello dla MS Windows, Lynx dla Unixa w trybie tekstowym i DOS-Lynx dla MS-DOS.
Należy tu uprzedzić, że ze względu na coraz powszechniejsze wykorzystanie grafiki w informacjach udostępnianych poprzez WWW wersje klientów nie posiadające mozliwości graficznych dają tylko częściowy dostęp do tych informacji. Tworząc nasz uczelniany server WWW (www.uci.agh.edu.pl, jest to kolejny alias dla galaxy.uci.agh.edu.pl, pełny URL ma postać http://www.uci.agh.edu.pl/) staraliśmy się konstruować strukturę danych tak, aby możliwe było dotarcie do wszelkich informacji z użyciem klienta czysto tekstowego. Nie znaczy to, że możliwe jest przedstawienie w ten sposób wszelkich informacji - np. zdjęcia, mapy czy wykresy z natury swej nie mogą być przedstawione w trybie tekstowym. Programy takie jak Lynx dopuszczają zapisanie informacji do zbioru w celu późniejszego przetwarzania (np. wydruku). Tak więc, głównym czynnikiem hamującym popularyzację WWW są możliwości sprzętowe - ok. 90% użytkowników USK korzysta z sieci za pośrednictwem komputerów PC pracujących w trybie tekstowym.
W celu uruchomienia programu Mosaic w wersji X Windows zainstalowanego na galaxy należy postępować zgodnie ze wskazówkami podanymi w rozdziale poświęconym X Windows. Komendą uruchamiającą program jest xmosaic, ewentualnie z parametrami - można np. podać URL dokumentu od którego Mosaic ma rozpoczać pracę.
Uruchomienie programu Lynx w systemie Unix sprowadza sie do wydania komendy lynx (również z opcjonalnymi parametrami).
DOS-Lynx (Lynx dla MS-DOS) stanowi na razie wersję eksperymentalną, wersja wolna od błędów powinna powstać w najbliższym czasie.
1. Peter Silvester System operacyjny Unix, WNT 1990, ISBN 83-204-1086-X.
2. Andrew S. Tanenbaum Sieci komputerowe, WNT 1988, ISBN 83-204-0964-0.
3. John F. Levine, Carol Baroudi Internet dla opornych, READ ME 1994, ISBN 83-85769-40-4.
4. Adrian Nye et al. X Windows Series, O'Reilly & Associates 1990.
5. Internet Engineering Task Force Requests For Comments (dokumenty dostępne przez WWW, ftp://ftp.cyf-kr.edu.pl/pub/mirror/rfc)
6. Brendan P. Kehoe Zen and the Art of Internet (dokument dostępny przez WWW, gopher://gopher.uci.agh.edu.pl/00/pub/docs/unix-beginners/zen)
7. Ed Krol RFC 1118. The Hitchhikers Guide to the Internet (dokument dostępny przez WWW, http://www.uci.agh.edu.pl/hitchhikers-guide/thgtti.html)
8. Adam Gaffin EFF's Extended Guide to the Internet (dokument dostępny przez WWW, http://www.uci.agh.edu.pl/eegtti/eegtti.html)
9. Kevin Hughes Entering the World-Wide Web: A Guide to Cyberspace (dokument dostępny przez WWW, http://www.uci.agh.edu.pl/guide.61.html/)
10. Scott Yanoff Inter-network Mail Guide (dokument dostępny przez WWW, http://alpha.acast.nova.edu/cgi-bin/inmgq.pl)
11. Tim Berners-Lee World Wide Web Initiative (dokument dostępny przez WWW, http://info.cern.ch/hypertext/WWW/TheProject)
12. Piotr Skibiński Co to jest IRC? (dokument dostępny przez WWW, http://www.ia.pw.edu.pl/irc/main_irc.html)
13. Rafał Maszkowski Polskie Zasoby Sieciowe (dokument dostępny przez WWW, http://www.uci.agh.edu.pl/pzs/pzs.html)
14. Wojciech Myszka Narzędzia sieciowe (dokument dostępny przez WWW, http://ldhp715.immt.pwr.wroc.pl/export_hp/tool/tool.html)
 Home page
Home page