|
|
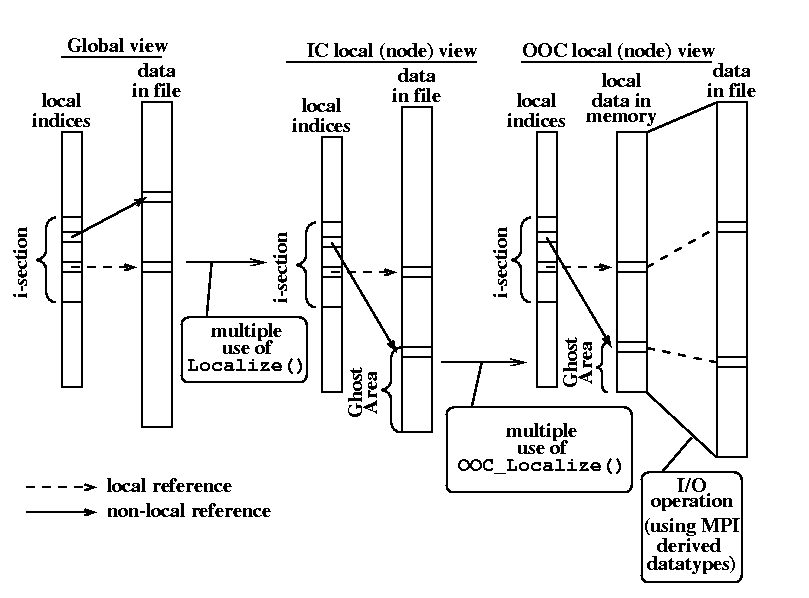
The idea of a new parallelizing scheme is presented in
Fig. ![[*]](../img/cross_ref_motif.gif) . The respective pseudocode
is shown in Fig. .
Since reading every element from a disk just as it becomes needed
would be very inefficient, the
optimization has to be aimed not only at efficient communication but
also at minimizing I/O accesses associated with not-in-memory data
elements. This is done by examining and translating the references to
data residing on a disk into references to the memory
buffer.
This is done by using the LIP_ooc_localize() routine
after LIP_localize() is called. The
translation process changes indices in the indirect array and in
communication schedule so they
point to the local memory buffer as shown in the Fig. .
This process results in a data structure
called I/O buffer mapping. It is updated upon examination of
subsequent i-sections to record information about what data has to be
moved between the disk and main memory as data that are in the memory are no
longer needed for the processing of the next i-section. After the
translation process is done, the I/O buffer mapping object may be used to
create MPI derived data types to perform actual movement of data using
MPI-IO routines (like MPI_File_read and
MPI_File_write()).
Obtaining MPI datatypes is
done via a call toLIP_IObufmap_get_datatype().
In this way the irregular
problems for which all arrays are OOC may also be parallelized.
. The respective pseudocode
is shown in Fig. .
Since reading every element from a disk just as it becomes needed
would be very inefficient, the
optimization has to be aimed not only at efficient communication but
also at minimizing I/O accesses associated with not-in-memory data
elements. This is done by examining and translating the references to
data residing on a disk into references to the memory
buffer.
This is done by using the LIP_ooc_localize() routine
after LIP_localize() is called. The
translation process changes indices in the indirect array and in
communication schedule so they
point to the local memory buffer as shown in the Fig. .
This process results in a data structure
called I/O buffer mapping. It is updated upon examination of
subsequent i-sections to record information about what data has to be
moved between the disk and main memory as data that are in the memory are no
longer needed for the processing of the next i-section. After the
translation process is done, the I/O buffer mapping object may be used to
create MPI derived data types to perform actual movement of data using
MPI-IO routines (like MPI_File_read and
MPI_File_write()).
Obtaining MPI datatypes is
done via a call toLIP_IObufmap_get_datatype().
In this way the irregular
problems for which all arrays are OOC may also be parallelized.

Next: Irregular distribution
Up: The Case of OOC
Previous: Dealing with OOC index-arrays
Contents
Created by Katarzyna Zając