Evolutionary multi-agent systems
While different forms of classical evolutionary computation use specific
representation, variation operators, and selection scheme, they all employ a
similar model of evolution -- they work on a given number of data structures
(population) and repeat the same cycle of processing (generation) consisting
of the selection of parents and production of offspring using variation
operators. Yet this model of evolution is much simplified and lacks many
important features observed in organic evolution [BacHamSch:TEC97], e.g.:
- dynamically changing environmental conditions,
- many criteria in consideration,
- neither global knowledge nor generational synchronisation assumed,
- co-evolution of species,
- evolving genotype-fenotype mapping.
At least some of these shortcomings may be avoided utilising the idea of
decentralised evolutionary computation, which may be realised as an
evolutionary multi-agent system (EMAS) as described below.
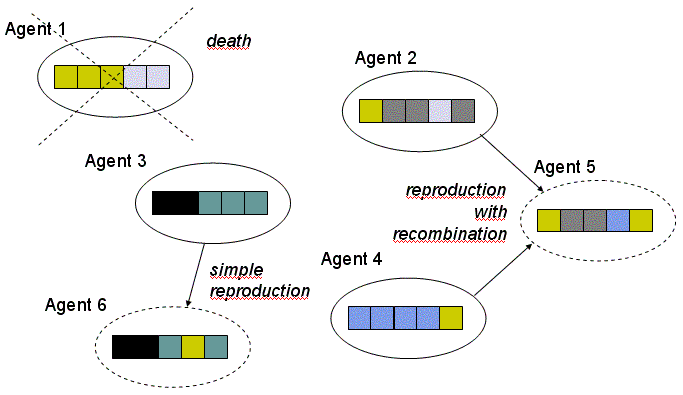
Fig. 1. Evolutionary multi-agent system
Following neodarwinian paradigms, two main components of the process of
evolution are \emph{inheritance} (with random changes of genetic information
by means of mutation and recombination) and \emph{selection}. They are
realised by the phenomena of death and reproduction, which may be easily
modelled as actions executed by agents \figref{fig:dzial}:
- action of death results in the elimination of the agent from
the system,
- action of reproduction is simply the production of a new agent
from its parent(s).
Inheritance is to be accomplished by an appropriate definition of
reproduction, which is similar to classical evolutionary algorithms. The set
of parameters describing core properties of the agent (genotype) is inherited
from its parent(s) -- with the use of mutation and recombination. Besides,
the agent may possess some knowledge acquired during its life, which is not
inherited. Both the inherited and acquired information determines the
behaviour of the agent in the system (phenotype).
Selection is the most important and most difficult element of the model of
evolution employed in EMAS. This is due to an assumed lack of global knowledge
(which makes it impossible to evaluate all individuals at the same time) and
autonomy of agents (which causes that reproduction is achieved
asynchronously). In such a situation selection mechanisms known from
classical evolutionary computation cannot be used. The proposed principle of
selection corresponds to its natural prototype and is based on the existence
of non-renewable resource, called \emph{life energy}. The energy is gained and
lost when the agent executes actions in the environment. Increase in energy is
a reward for 'good' behaviour of the agent, decrease -- a penalty for 'bad'
behaviour (which behaviour is considered 'good' or 'bad' depends on the
particular problem to be solved). At the same time the level of energy
determines actions the agent is able to execute. In particular, low energy
level should increase possibility of death and high energy level should
increase possibility of reproduction.
A more precise description of this model and its advantages may be found in
[my:ICMAS96,my:IAI2001]. In short, EMAS should enable the
following:
- local selection allows for an intensive exploration of the search space,
which is similar to parallel evolutionary algorithms,
- the way phenotype (behaviour of the agent) is developed from genotype
(inherited information) depends on its interaction with the environment,
- self-adaptation of the population size is possible when appropriate
selection mechanisms are used.
What is more, explicitly defined living space facilitates an implementation
in a distributed computational environment.
|

