Next: Conclusion Up: Illustrative examples Previous: Browsing a tree structure Contents
The aggregation, or an aggregate select, allows to group some data (records) according to the given key and perform some within-group calculations i.e.: finding maximum or minimum value in the group, number of records in the group, or other statistical calculations (see Section 2.1).
The Reverse Aggregation works exactly in an opposite way. It selects records which satisfy the given grouping criterion. In other words, it finds all acceptable solutions of a given problem. In general this is a search for subsets in a given set. The problem is formally defined in Section 2.4 - it is a search for admissible solutions. The example addresses the problem class C2 (see Section 2.2).
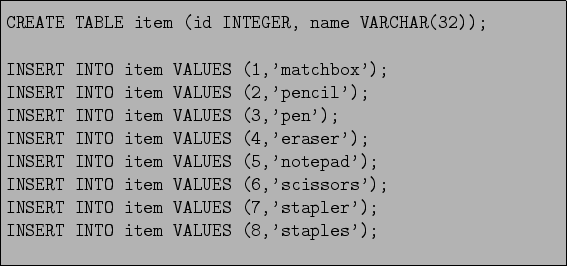
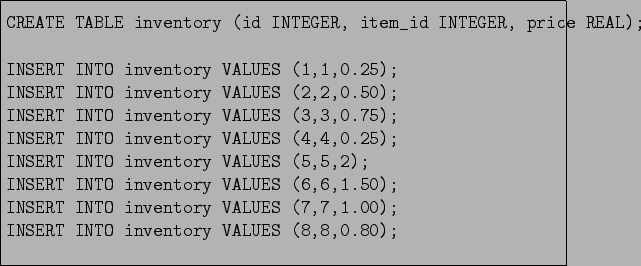
The problem can be stated as follows: ``what can I buy from the given inventory, having a given amount of money?''. The inventory is defined as two relations: item and inventory. The item (Figure 12.4) holds item names, while the inventory (see Figure 12.5) holds the inventory which states about currently available items and their prices. There is a one-to-many relationship between the item and inventory by item_id attribute.
Figure 12.6 contains the Logic Program which provides the Reverse Aggregation Sum. The Logic Program has to be decomposed and the Internal Matching and External Matching records have to be added.
The External Matching (see Figure 12.7) establishes a relationship between the relation shop, which can be used in the user query, and the predicate listtosol, which serves as the goal to generate inferred records. The attribute major is a group index, while the attribute minor is an index within the group. The Logic Program has access to the database by the predicate price/3 which is mapped onto the inventory relation.
The user query: ``What can I buy for $0.50 ?'' can be expressed as:
SELECT item, major, minor, price, name
FROM shop('SELECT 0.50',,,) s,item, inventory
WHERE item.id=s.item
AND item.id=inventory.item_id
ORDER BY major, minor;
The system replies:
| item | major | minor | price | name |
| 4 | 0 | 0 | 0.25 | eraser |
| 4 | 0 | 1 | 0.25 | eraser |
| 4 | 1 | 0 | 0.25 | eraser |
| 1 | 1 | 1 | 0.25 | matchbox |
| 4 | 2 | 0 | 0.25 | eraser |
| 2 | 3 | 0 | 0.5 | pencil |
| 1 | 4 | 0 | 0.25 | matchbox |
| 4 | 4 | 1 | 0.25 | eraser |
| 1 | 5 | 0 | 0.25 | matchbox |
| 1 | 5 | 1 | 0.25 | matchbox |
| 1 | 6 | 0 | 0.25 | matchbox |
| item | major | minor | price | name |
| 4 | 0 | 0 | 0.25 | eraser |
| 4 | 0 | 1 | 0.25 | eraser |
| item | major | minor | price | name |
| 4 | 1 | 0 | 0.25 | eraser |
| 1 | 1 | 1 | 0.25 | matchbox |
| item | major | minor | price | name |
| 4 | 2 | 0 | 0.25 | eraser |
| item | major | minor | price | name |
| 2 | 3 | 0 | 0.5 | pencil |
| item | major | minor | price | name |
| 1 | 4 | 0 | 0.25 | matchbox |
| 4 | 4 | 1 | 0.25 | eraser |
| item | major | minor | price | name |
| 1 | 5 | 0 | 0.25 | matchbox |
| 1 | 5 | 1 | 0.25 | matchbox |
| item | major | minor | price | name |
| 1 | 6 | 0 | 0.25 | matchbox |
The Reverse Aggregation can lead easily to a combinatorial explosion. Changing the amount of available funds in the query from $0.50 to $2.00, increases number of generated records from 11 to 15413. The timing comparison is given below.
funds=$2.00
# records: 15413
real 0m13.979s
user 0m3.350s
sys 0m0.540s
funds=$1.00
# records: 157
real 0m0.368s
user 0m0.100s
sys 0m0.030s
In such a case the RDBMS overhead becomes more significant than the inference time.
Igor Wojnicki 2005-11-07
![\begin{figure}\begin{verbatim}index(X,N,[X\vert T]):- length(T,N).
index(X,N,[...
...st,Major,L),
index(Item,Minor,Sublist).\end{verbatim}\centering
\end{figure}](img256.png)
