This is an old revision of the document!
Table of Contents
Laboratorium 1+2
Celem laboratorium jest implementacja prostych programów w języku Java przetwarzających dane na platformie Apache Spark.
Ponieważ materiał jest nowy - ocenimy w trakcie zajęć ile udało się zrealizować i ewentualnie będziemy kontynuowali na kolejnych zajęciach.
Literatura:
- Jean-Georges Perrin, Spark in Action, 2020
Oprogramowanie
- JDK 17 (Spark jest kompatybilny z JDK 8, 11 i 17)
- InteliJ Idea (lub alternatywne IDE)
- Opcjonalnie: maven
- PostgreSQL (przetestujemy zapis do bazy danych)
- Przyda się w do wizualizacji: lokalna instalacja języka Python z numpy i matplotlib
- Przyda się w przyszłości: docker
Projekt
Tworzymy projekt oparty na Mavenie, a następnie modyfikujemy pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>pl.edu.agh.isi</groupId> <artifactId>eksploracja-danych</artifactId> <version>1.0-SNAPSHOT</version> <properties> <java.version>17</java.version> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <scala.version>2.13</scala.version> <spark.version>3.5.0</spark.version> <junit.version>4.13.1</junit.version> <maven-compiler-plugin.version>3.8.1</maven-compiler-plugin.version> </properties> <dependencies> <!-- Spark --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.version}</artifactId> <version>${spark.version}</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_${scala.version}</artifactId> <version>${spark.version}</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>${junit.version}</version> <scope>test</scope> </dependency> <dependency> <groupId>com.github.sh0nk</groupId> <artifactId>matplotlib4j</artifactId> <version>0.5.0</version> </dependency> <dependency> <groupId>org.postgresql</groupId> <artifactId>postgresql</artifactId> <version>42.7.2</version> </dependency> </dependencies> <!-- Build --> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>${maven-compiler-plugin.version}</version> <configuration> <source>${java.version}</source> <target>${java.version}</target> </configuration> </plugin> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <version>3.1.0</version> <configuration> <executable>java</executable> <arguments> <argument>--add-exports</argument> <argument>java.base/sun.nio.ch=ALL-UNNAMED</argument> <argument>-classpath</argument> <classpath /> <argument>org.example.Main</argument> </arguments> </configuration> </plugin> </plugins> </build> </project>
Niektóre zależności są opcjonalne:
matplotlib4j- biblioteka, pozwalająca na wywołanie bibliotekimatplotlibz programu Javapostgresql- driver JDBC pozwalający na zapis do bazy danych PostgreSQLexec-maven-plugin- uruchamianie programu za pomocą mavena
Aby uruchomić program za pomocą mavena, należey go
zbudować:
mvn install
uruchomić (korzystając z exec-maven-plugin):
mvn exec:exec
Główna klasa i konfiguracja
Napiszemy minimalistyczną klasę Main z funkcją main()
public class Main { public static void main(String[] args) { // ArrayToDatasetApp.main(null); } }
Następnie zdefiniujemy dla niej konfigurację Run configuration

Uruchomienie aplikacji Apache Spark w wersji Javy>9 (po wprowadzeniu modułów) wymaga ustawienia dodatkowych opcji maszyny wirtualnej.
Zazwyczaj niezbędne (i wystarczające) jest dodanie opcji:
--add-exports=java.base/sun.nio.ch=ALL-UNNAMED
Tę opcję należy wprowadzić w oknie dialogowym
W przypadku dostępu do różnych źródeł danych za pomocą biblioteki databricks może być niezbędne rozszerzenie tej listy
--add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.lang.invoke=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.net=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.util.concurrent=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/sun.nio.cs=ALL-UNNAMED --add-opens=java.base/sun.security.action=ALL-UNNAMED --add-opens=java.base/sun.util.calendar=ALL-UNNAMED
na podstawie tej dyskusji
Pisząc kolejne klasy, będziemy ich kod umieszczali w statycznej publicznej funkcji (np. po prostu main) i wywoływali tę funkcję z Main.main(). Dzieki temu unikniemy konieczności wielokrotnego definiowania konfiguracji dla każdego przykładu.
Weryfikacja poprawności konfiguracji
Dodaj i uruchom poniższy kod - wołając z Main.main().
import java.util.Arrays; import java.util.List; public class ArrayToDatasetApp { public static void main(String[] args) { SparkSession spark = SparkSession.builder() .appName("Array to Dataset") .master("local") .getOrCreate(); List<String> data = Arrays.asList( "Victor Skinner", "Boris Howard", "Richard Avery", "Simon Metcalfe", "Robert Black"); Dataset<String> ds = spark.createDataset(data, Encoders.STRING()); ds.show(); ds.printSchema(); Dataset<Row> df = ds.toDF(); df.show(); df.printSchema(); } }
Ładowanie i konwersja danych
Pliki
Wykorzystamy następujące pliki:
Ich opis zamieszczony jest na tej stronie: https://home.agh.edu.pl/~pszwed/wiki/doku.php?id=pz1:java-movielens
Users
public class LoadUsers { public static void main(String[] args) { SparkSession spark = SparkSession.builder() .appName("LoadUsers") .master("local") .getOrCreate(); System.out.println("Using Apache Spark v" + spark.version()); Dataset<Row> df = spark.read() .format("csv") .option("header", "true") .load("data/movielens/users.csv"); System.out.println("Excerpt of the dataframe content:"); df.show(20); System.out.println("Dataframe's schema:"); df.printSchema(); } }
Aby skorygować typy danych możemy przed załadowaniem pliku zdefiniować jego schemat.
StructType schema = DataTypes.createStructType(new StructField[] { DataTypes.createStructField( "userId", DataTypes.IntegerType, true), DataTypes.createStructField( "foreName", DataTypes.StringType, false), DataTypes.createStructField( "surName", DataTypes.StringType, false), DataTypes.createStructField( "email", DataTypes.StringType, false), }); Dataset<Row> df = spark.read() .format("csv") .option("header", "true") .schema(schema) .load("data/movielens/users.csv");
Wynik
root |-- userId: integer (nullable = true) |-- foreName: string (nullable = true) |-- surName: string (nullable = true) |-- email: string (nullable = true)
Najczęściej wystarczy zastosować opcję inferSchema
Dataset<Row> df = spark.read() .format("csv") .option("header", "true") // .schema(schema) .option("inferSchema", true) .load("data/movielens/users.csv");
ale tracimy np. kotrole nad opcją nullable (która może być pożądana przy zapisie do bazy danych).
Movies
Dane o filmach zawierają niestrukturalne elementy:
- rok produkcji umieszczony w nawiasach
- Listę gatunków oddzielonych pionowymi kreskami
movieId,title,genres 1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy 2,Jumanji (1995),Adventure|Children|Fantasy 3,Grumpier Old Men (1995),Comedy|Romance 4,Waiting to Exhale (1995),Comedy|Drama|Romance 5,Father of the Bride Part II (1995),Comedy 6,Heat (1995),Action|Crime|Thriller 7,Sabrina (1995),Comedy|Romance 8,Tom and Huck (1995),Adventure|Children 9,Sudden Death (1995),Action 10,GoldenEye (1995),Action|Adventure|Thriller
Ładowanie danych
Napisz kod, który podobnie jak w przypadku użytkowników, ładuje zbiór danych do obiektu Dataset<Row> df.
Wydzielanie roku produkcji i tytułu
Dane te mają stać się nowymi kolumnami zbioru danych otrzymanego w wyniku transformacji.
- Aby dodać nową kolumnę należy skorzystać z funkcji
withColumn(String colName, Column col). Jej opis znajduje się w dokumentacji klasy Dataset - Z kolei drugi argument (kolumna) może zostać uzyskany w wyniky wywołania jednej z funkcji Apache Spark. Są one odpowiednikami funkcji SQL i ich nazwy są spójne dla wszystkich interfejsów: Scala, Java i Python.
Czyli na przykład poniższy kod:
var df2=df .withColumn("rok",year(now())) .withColumn("miesiac",month(now())) .withColumn("dzien",day(now())) .withColumn("godzina",hour(now())); df2.show(5); df2.printSchema();
doda cztery kolumny z wydzielonymi fragmentami daty i czasu
+-------+--------------------+--------------------+----+-------+-----+-------+ |movieId| title| genres| rok|miesiac|dzien|godzina| +-------+--------------------+--------------------+----+-------+-----+-------+ | 1| Toy Story (1995)|Adventure|Animati...|2024| 2| 27| 13| | 2| Jumanji (1995)|Adventure|Childre...|2024| 2| 27| 13| | 3|Grumpier Old Men ...| Comedy|Romance|2024| 2| 27| 13| | 4|Waiting to Exhale...|Comedy|Drama|Romance|2024| 2| 27| 13| | 5|Father of the Bri...| Comedy|2024| 2| 27| 13| +-------+--------------------+--------------------+----+-------+-----+-------+
Do wydzielenia tekstu użyj funkcji Column regexp_extract(Column e, String exp, int groupIdx)
var df_transformed = df .withColumn("title2",regexp_extract(...)) .withColumn("year",regexp_extract(...)) .drop("title") .withColumnRenamed("title2","title"); df_transformed.show();
- Aby odwołać się do kolumny o danej nazwie, użyj funkcji
col(“nazwa”) - Jakiego wyrażenie regularnego użyć? Na przykład: “^(.*?)\\s*\\((\\d{4})\\)$”
- Pierwsza grupa: od początku do spacji poprzedzającej nawias. Grupy są zdefiniowane w nawiasach
(grupa), natomiast nawiasy jako\\( - Potem spacje i nawias do pominięcia
- Kolejna grupa to cztery cyfry
- Nawias do pominięcia
Można poeksperymentować:
public static void main(String[] args) { String input = "Movie title (from the database) (2023)"; // Define a regular expression pattern to match the movie title and year Pattern pattern = Pattern.compile("^(.*?)\\s*\\((\\d{4})\\)$"); // Create a Matcher object Matcher matcher = pattern.matcher(input); // Check if the pattern matches the input string if (matcher.matches()) { // Extract the movie title and year from the matched groups String movieTitle = matcher.group(1); String year = matcher.group(2); // Print the results System.out.println("Movie Title: " + movieTitle); System.out.println("Year: " + year); } else { System.out.println("Invalid input format"); } }
Gatunki: zamieniamy tekst na tablicę
Dodaj kolumnę “genres_array” utworzoną w wyniku wywołania funkcji Column split(Column str, String pattern). Użyj wzorzec postaci “\\|”.
Gatunki: rozbicie tablicy (explode)
Operacja explode tworzy osobny wiersz dla każdego elementu tablicy. Czyli po zastosowaniu transformacji explode(col(“genres_array”)), umieszczeniu wyniku w kolumnie genre i usunieciu genres_array powinniśmy otrzymać następujący wunik:
+-------+---------+----------------+----+ |movieId| genre| title|year| +-------+---------+----------------+----+ | 1|Adventure| Toy Story|1995| | 1|Animation| Toy Story|1995| | 1| Children| Toy Story|1995| | 1| Comedy| Toy Story|1995| | 1| Fantasy| Toy Story|1995| | 2|Adventure| Jumanji|1995| | 2| Children| Jumanji|1995| | 2| Fantasy| Jumanji|1995| | 3| Comedy|Grumpier Old Men|1995| | 3| Romance|Grumpier Old Men|1995| +-------+---------+----------------+----+
Konwersja one-hot
Sprawdzimy, jaka jest lista gatunków tworząc nowy zbiór danych z nazwami gatunków, a następnie zamienimy go na listę
df_exploded.select("genre").distinct().show(false); var genreList = df_exploded.select("genre").distinct().as(Encoders.STRING()).collectAsList(); for(var s:genreList){ System.out.println(s); }
Aby przeprowadzić konwersję one-hot należy:
- Dodać kolumny o nazwach odpowiadających elementom listy
- Dla każdego gatunku
sWstawić wartości true lub false do kolumnysna podstawie testu, czy tablica gatunków zawiera ten element.
Sprawdź, czy poniższy kod zadziała. Pomijanie “(no genres listed)” jest dyskusyjne…
var df_multigenre = df_transformed; for(var s:genreList){ if(s.equals("(no genres listed)"))continue; df_multigenre=df_multigenre.withColumn(s,array_contains(col("genres_array"),s)); }
Ratings
Załaduj dane z pliku ratings.csv i wyświetl schemat.
Oczekiwany wynik:
+------+-------+------+---------+ |userId|movieId|rating|timestamp| +------+-------+------+---------+ | 1| 1| 4.0|964982703| | 1| 3| 4.0|964981247| | 1| 6| 4.0|964982224| | 1| 47| 5.0|964983815| | 1| 50| 5.0|964982931| +------+-------+------+---------+ root |-- userId: integer (nullable = true) |-- movieId: integer (nullable = true) |-- rating: double (nullable = true) |-- timestamp: integer (nullable = true)
Przetwarzanie daty i czasu
Kolumna timestamp to data zakodowana w formacie UNIXa jako liczba sekund od 01.01.1970:00.00.
Można zmienić jej typ danych na datetime za pomocą funkcji from_unixtime(Col col).
Czyli poniższe wywołanie doda kolumnę z odpowiednim typem danych:
.withColumn("datetime", functions.from_unixtime(df.col("timestamp")))
Dodaj kolumny datetime, year, month, day pobierając składniki daty za pomocą odpowiednich funkcji.
Oczekiwany rezultat:
+------+-------+------+---------+-------------------+----+-----+---+ |userId|movieId|rating|timestamp| datetime|year|month|day| +------+-------+------+---------+-------------------+----+-----+---+ | 1| 1| 4.0|964982703|2000-07-30 20:45:03|2000| 7| 30| | 1| 3| 4.0|964981247|2000-07-30 20:20:47|2000| 7| 30| | 1| 6| 4.0|964982224|2000-07-30 20:37:04|2000| 7| 30| | 1| 47| 5.0|964983815|2000-07-30 21:03:35|2000| 7| 30| | 1| 50| 5.0|964982931|2000-07-30 20:48:51|2000| 7| 30| +------+-------+------+---------+-------------------+----+-----+---+ only showing top 5 rows root |-- userId: integer (nullable = true) |-- movieId: integer (nullable = true) |-- rating: double (nullable = true) |-- timestamp: integer (nullable = true) |-- datetime: string (nullable = true) |-- year: integer (nullable = true) |-- month: integer (nullable = true) |-- day: integer (nullable = true)
Statystyki
Chcemy policzyć, ile było ocen w kolejnych latach i miesiącach… Uzupełnij poniższy kod.
var df_stats_ym = df_transformed.groupBy(??,??)).count().orderBy(??,??); df_stats_ym.show(1000);
Wyświetlanie
Wyświetlanie wykresów w języku Java ma swoje ograniczenia. Ładne wykresy można tworzyć w JavaFX. Użycie popularnej biblioteki JFreeChart wymaga sporo kodowania, a wykresy nie są zbyt atrakcyjne.
Użyjemy biblioteki matplotlib4j, która pozwala na wywołanie części funkcji biblioteki Pythona matplotlib z języka Java. Na potrzeby wizualizacji będzie to wystarczające. https://github.com/sh0nk/matplotlib4j/blob/master/docs/tutorial.md
Aby uruchomić funkcję do wyświetlanie wykresów musi być zainstalowany interpreter języka Python i podstawowe biblioteki, w tym matplotlib.
Alternatywą może być zapis Dataset do pliku CSV i dalsze przetwarzanie za pomocą dowolnego narzędzia (nawet Excela).
Wykresy wyświetlimy za pomocą ponższej funkcji:
static void plot_stats_ym(Dataset<Row> df, String title, String label) { var labels = df.select(concat(col("year"), lit("-"), col("month"))).as(Encoders.STRING()).collectAsList(); var x = NumpyUtils.arange(0, labels.size() - 1, 1); x = df.select(expr("year+(month-1)/12")).as(Encoders.DOUBLE()).collectAsList(); var y = df.select("count").as(Encoders.DOUBLE()).collectAsList(); Plot plt = Plot.create(); plt.plot().add(x, y).linestyle("-").label(label); plt.legend(); plt.title(title); try { plt.show(); } catch (IOException e) { throw new RuntimeException(e); } catch (PythonExecutionException e) { throw new RuntimeException(e); } }
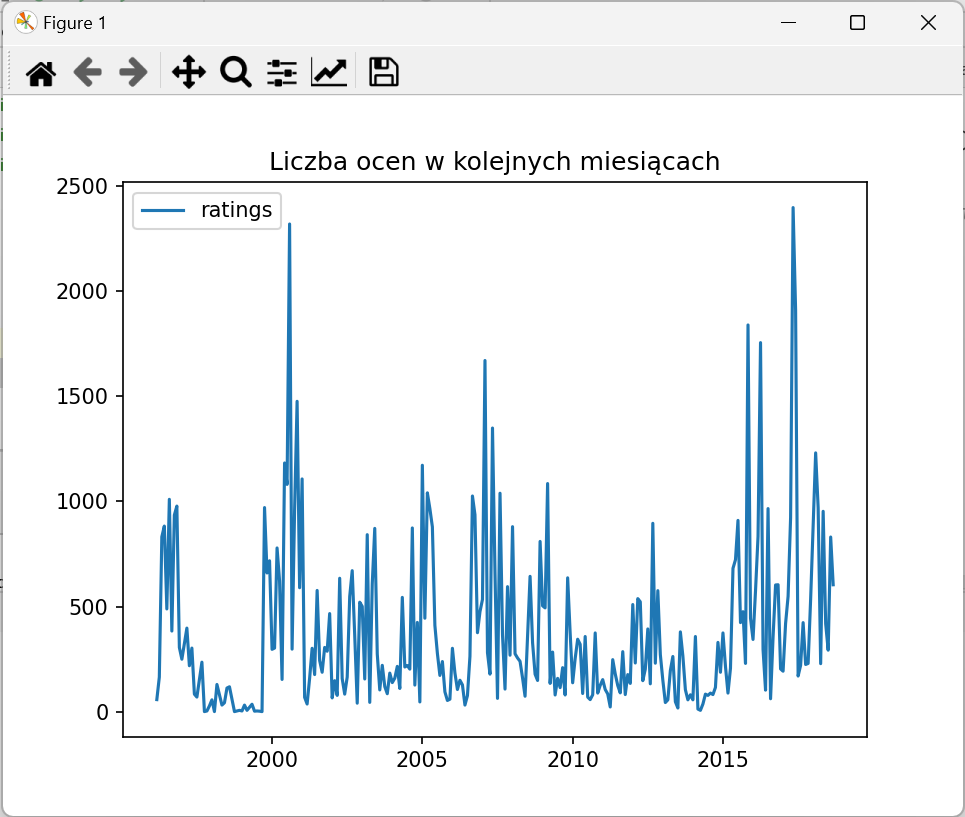
Ciekawsze funkcje:
concat()łączy zawartość kolumnyyearz literałem (stałą tekstową) i kolumnąmonthexpr(“year+(month-1)/12”)wyrażenie SQL działające na kolumnach- as(Encoders.DOUBLE()) zamienia wiersze zbioru danych na obiekt wskazanego typu
Tags
1. Załaduj plik tags.csv i wyświetl informacje o jego zawartości i schemacie danych
+------+-------+---------------+----------+ |userId|movieId| tag| timestamp| +------+-------+---------------+----------+ | 2| 60756| funny|1445714994| | 2| 60756|Highly quotable|1445714996| | 2| 60756| will ferrell|1445714992| | 2| 89774| Boxing story|1445715207| | 2| 89774| MMA|1445715200| +------+-------+---------------+----------+ only showing top 5 rows Dataframe's schema: root |-- userId: integer (nullable = true) |-- movieId: integer (nullable = true) |-- tag: string (nullable = true) |-- timestamp: integer (nullable = true)
2. Analogicznie, jak poprzednio, przekonwertuj zawartość kolumny timestamp
+------+-------+---------------+----------+-------------------+----+-----+---+ |userId|movieId| tag| timestamp| datetime|year|month|day| +------+-------+---------------+----------+-------------------+----+-----+---+ | 2| 60756| funny|1445714994|2015-10-24 21:29:54|2015| 10| 24| | 2| 60756|Highly quotable|1445714996|2015-10-24 21:29:56|2015| 10| 24| | 2| 60756| will ferrell|1445714992|2015-10-24 21:29:52|2015| 10| 24| | 2| 89774| Boxing story|1445715207|2015-10-24 21:33:27|2015| 10| 24| | 2| 89774| MMA|1445715200|2015-10-24 21:33:20|2015| 10| 24| +------+-------+---------------+----------+-------------------+----+-----+---+ only showing top 5 rows root |-- userId: integer (nullable = true) |-- movieId: integer (nullable = true) |-- tag: string (nullable = true) |-- timestamp: integer (nullable = true) |-- datetime: string (nullable = true) |-- year: integer (nullable = true) |-- month: integer (nullable = true) |-- day: integer (nullable = true)
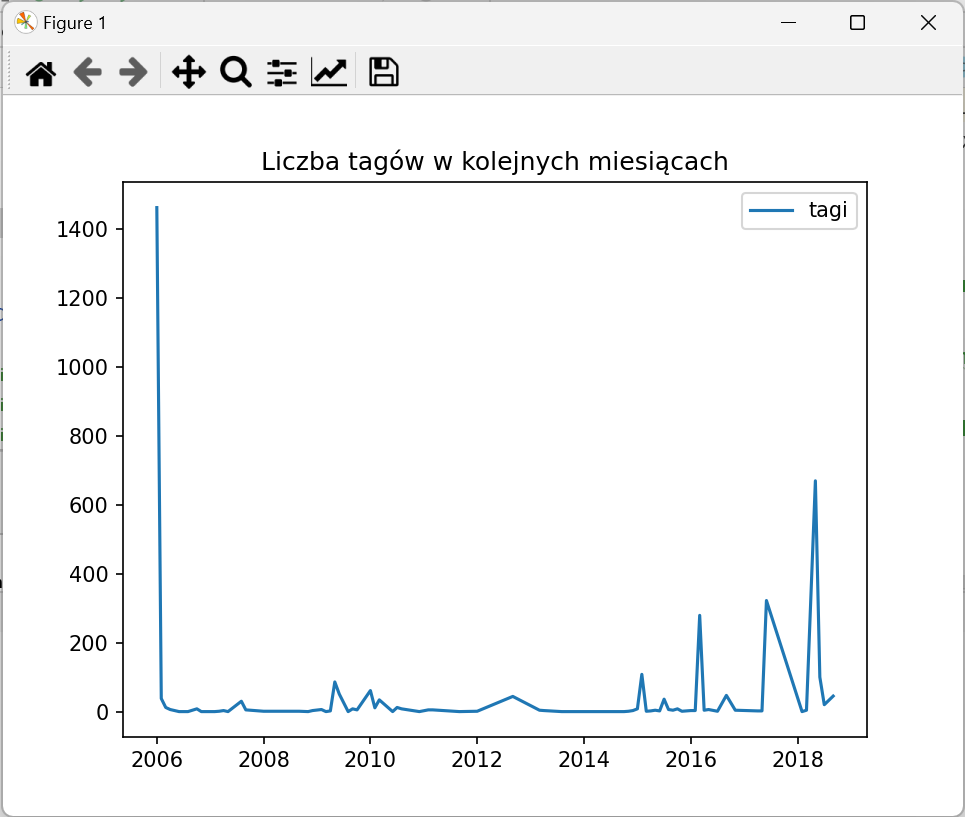
3. Policz liczbę tagów w kolejnych miesiącach
+----+-----+-----+ |year|month|count| +----+-----+-----+ |2006| 1| 1462| |2006| 2| 39| |2006| 3| 13| |2006| 4| 7| |2006| 6| 1| +----+-----+-----+
4. Wyświetl wykres
Join MoviesRatings
1. Załaduj plik movies.csv do zbioru df_movies
2. Dodaj kolumnę z rokiem produkcji
3. Załaduj dane z raings.csv do zmiennej df_ratings
Wykonaj operację join
var df_mr = df_movies.join(df_ratings,df_movies.col("movieId").equalTo(df_ratings.col("movieId")));
Jeżeli nazwy kolumn są identyczne, można użyć:
var df_mr = df_movies.join(df_ratings,"movieId","inner");
4. Zgrupuj dane po tytule używając funkcji groupBy() i dodając kolumny:
- z minimalną oceną - nazwa kolumny
min_rating- użyj funkcjialias()do zmiany nazwy - średnią ocen o nazwie
avg_rating - maksymalną oceną - nazwa kolumny
max_rating - liczbą ocen - nazwa kolumny
rating_cnt
Posortuj po liczbie ocen (malejąco).
Oczekiwany (przykładowy) wynik:
+--------------+----------+------------------+----------+----------+ | title|min_rating| avg_rating|max_rating|rating_cnt| +--------------+----------+------------------+----------+----------+ | Forrest Gump| 0.5| 4.164133738601824| 5.0| 1316| | Pulp Fiction| 0.5| 4.197068403908795| 5.0| 1228| | Toy Story| 0.5|3.9209302325581397| 5.0| 1075| |Lion King, The| 1.0| 3.941860465116279| 5.0| 1032| | Shrek| 0.5|3.8676470588235294| 5.0| 1020| +--------------+----------+------------------+----------+----------+
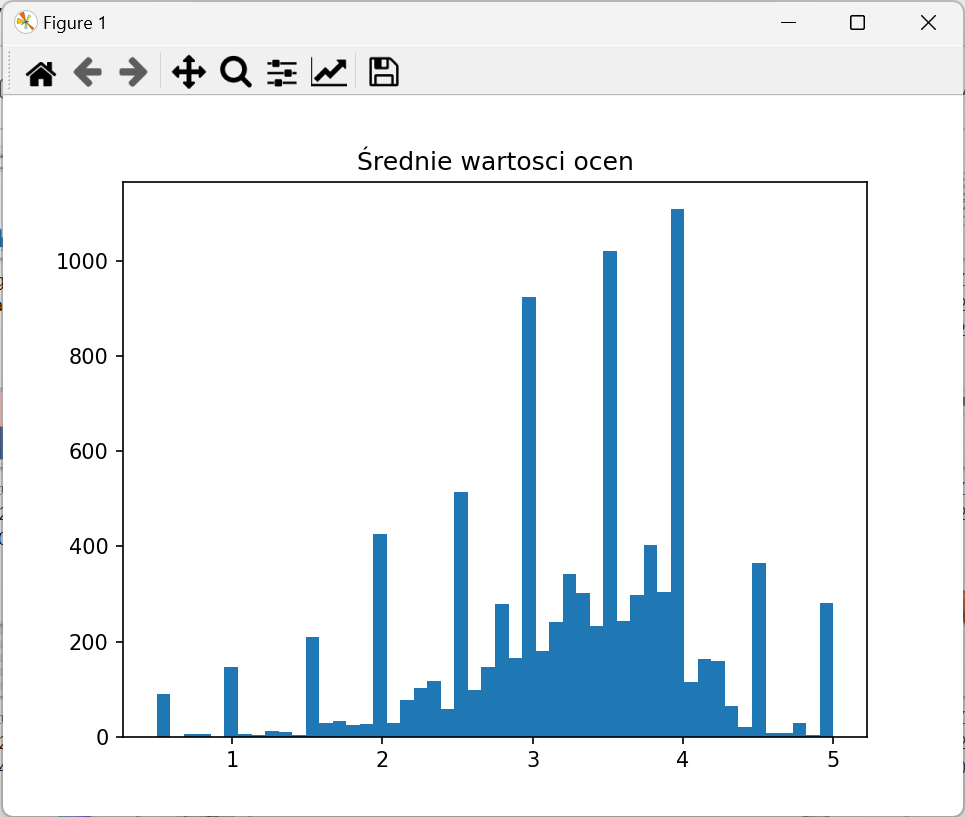
6. Wyświetl histogram wartości avg_rating za pomocą poniższej funkcji.
static void plot_histogram(List<Double> x, String title) { Plot plt = Plot.create(); plt.hist().add(x).bins(50); plt.title(title); try { plt.show(); } catch (IOException e) { throw new RuntimeException(e); } catch (PythonExecutionException e) { throw new RuntimeException(e); } }
Pobierz dane z kolumny za pomocą funkcji select
var avgRatings = df_mr_t.select("avg_rating").where("rating_cnt>=0").as(Encoders.DOUBLE()).collectAsList();
Oczekiwany wynik:
5. Pobierz wartości z kolumny rating_cnt dla rekordów spełniających avg_rating>=4.5. Warunek przekaż jako parametr funkcji where(). Następnie przekonwertuj na zmienną typu List<Double>.
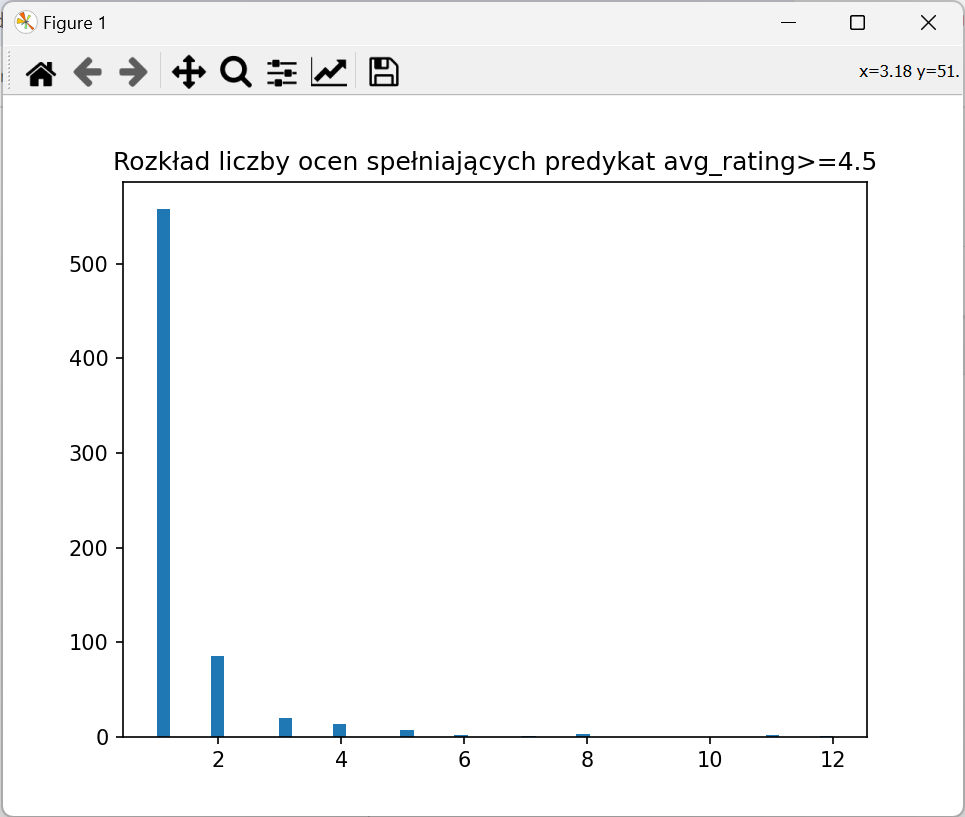
8. Wprowadź bardziej złożony warunek, np. koniunkcję i wyświetl wynik
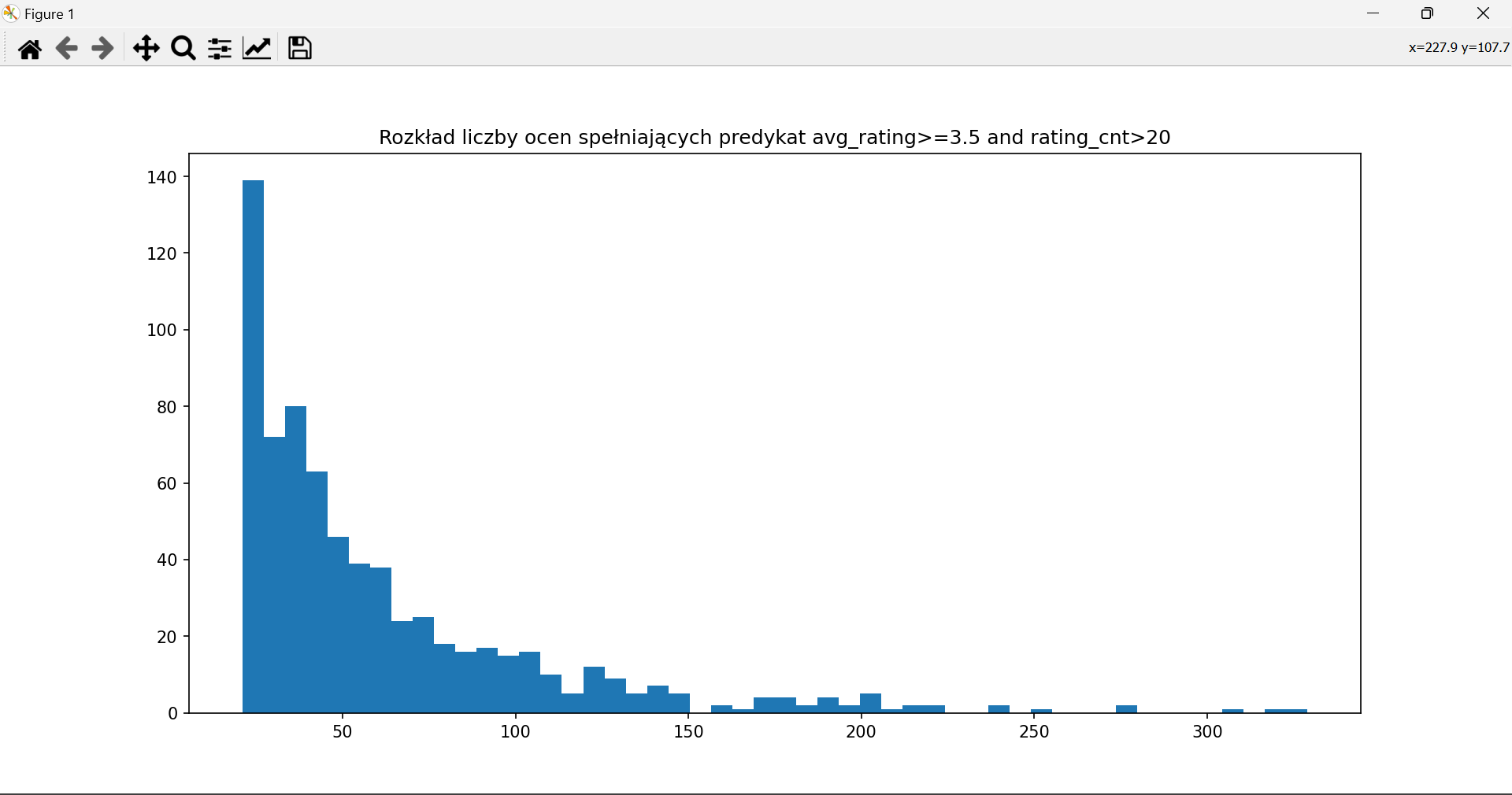
Przez jaki czas od produkcji filmu pojawiały się oceny?
1. Dodaj kolumnę release_to_rating_year nadając jej wartośc wyrażenia będącego róznicą roku pobranego z kolumny datetime (data i czas publikacji oceny) oraz year (pochodzącej z tytułu filmu).
Zbiór danych powinien mieć zawartość, jak poniżej:
+-------+--------------------+--------------------+----+------+-------+------+-------------------+----------------------+ |movieId| genres| title|year|userId|movieId|rating| datetime|release_to_rating_year| +-------+--------------------+--------------------+----+------+-------+------+-------------------+----------------------+ | 1|Adventure|Animati...| Toy Story|1995| 1| 1| 4.0|2000-07-30 20:45:03| 5.0| | 3| Comedy|Romance| Grumpier Old Men|1995| 1| 3| 4.0|2000-07-30 20:20:47| 5.0| | 6|Action|Crime|Thri...| Heat|1995| 1| 6| 4.0|2000-07-30 20:37:04| 5.0| | 47| Mystery|Thriller|Seven (a.k.a. Se7en)|1995| 1| 47| 5.0|2000-07-30 21:03:35| 5.0| | 50|Crime|Mystery|Thr...| Usual Suspects, The|1995| 1| 50| 5.0|2000-07-30 20:48:51| 5.0| +-------+--------------------+--------------------+----+------+-------+------+-------------------+----------------------+
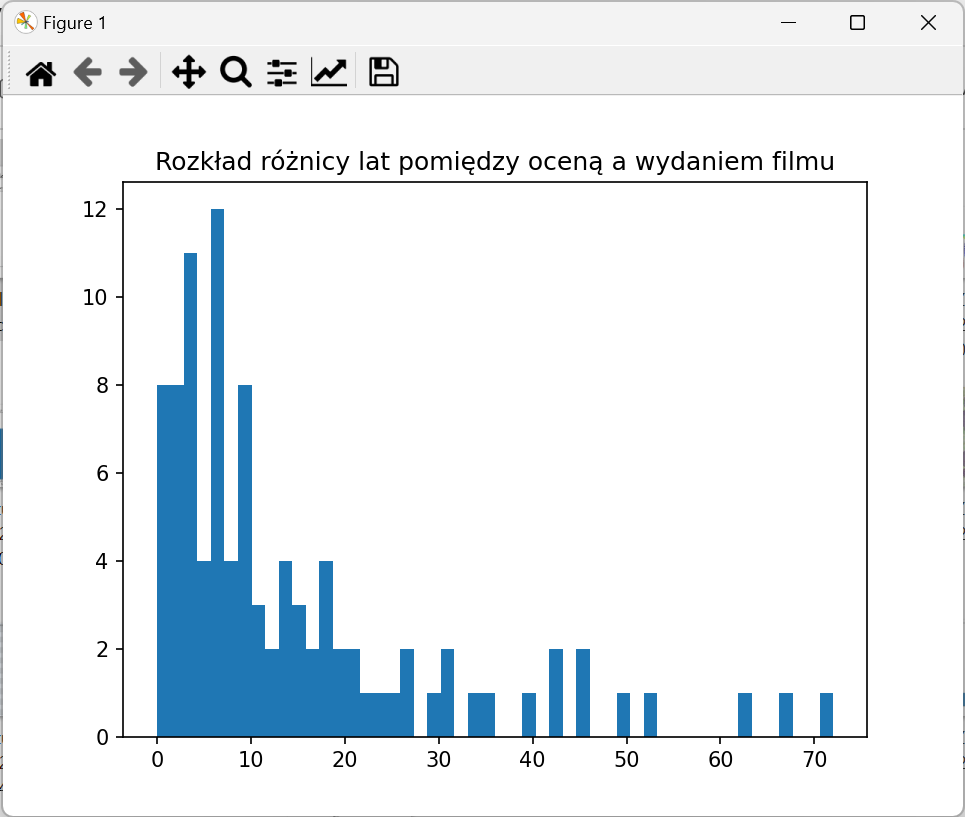
2. Pobierz listę wartości i wyświetl histogram.
![]() Nie działa…
Nie działa…
Przy wizualizacji natrafiamy na wąskie gardło. Lista wartości przekazywana jest do funkcji matplotlib poprzez standardowe wejście, a jest ona dośc duża - ma około 100000 elementów.
3. Przeprowadź downsampling używając funkcji sample(ratio). Dobierz parametr eksperymentalnie.
Oczekiwany wynik:
4. Zgrupuj dane po kolumnie release_to_rating_year obliczając liczbę wystąpień. Nowa kolumna ze zagregowanymi dnaymi powinna otrzymać nazwę count. Posortuj dane po release_to_rating_year.
Oczekiwany wynik:
+----------------------+-----+ |release_to_rating_year|count| +----------------------+-----+ | NULL| 100| | -1.0| 3| | 0.0| 3809| | 1.0| 9876| | 2.0| 7389| | 3.0| 5788| | 4.0| 4695| | 5.0| 4381| | 6.0| 4197| | 7.0| 3891| ...
Dlaczego pojawiły się wartości NULL? Przefiltruj dane:
var df_mr2 = df_mr.filter("release_to_rating_year=-1 OR release_to_rating_year IS NULL"); df_mr2.show(105);
- Czasem nie ma daty – tego nie da się zmienić
- Czasem rekord ma następującą postać:
“94494,96 Minutes (2011) ,Drama|Thriller”.
5. Popraw wyrażenie regularne służące do wydzielania tytułu i roku produkcji, aby akceptowało dowolną liczbę spacji po nawiasie zamykającym rok. O ile zmniejszy się liczba wartości NULL?
6. Podczas przetwarzania filmów - w przypadku, kiedy brakuje daty w tytule użyj wartości z kolumny title. Służą do tego funkcje when(condition, columnToUse).otherwise(anotherColumnToUse)
... .withColumn("title2", when(regexp_extract(col("title"),"^(.*?)\\s*\\((\\d{4})\\)\\s*$",1).equalTo("") ,col("title")) .otherwise(regexp_extract(col("title"),"^(.*?)\\s*\\((\\d{4})\\)\\s*$",1))) ...
Nie zmieni to wartości NULL, ale zostanie zachowany tytuł…
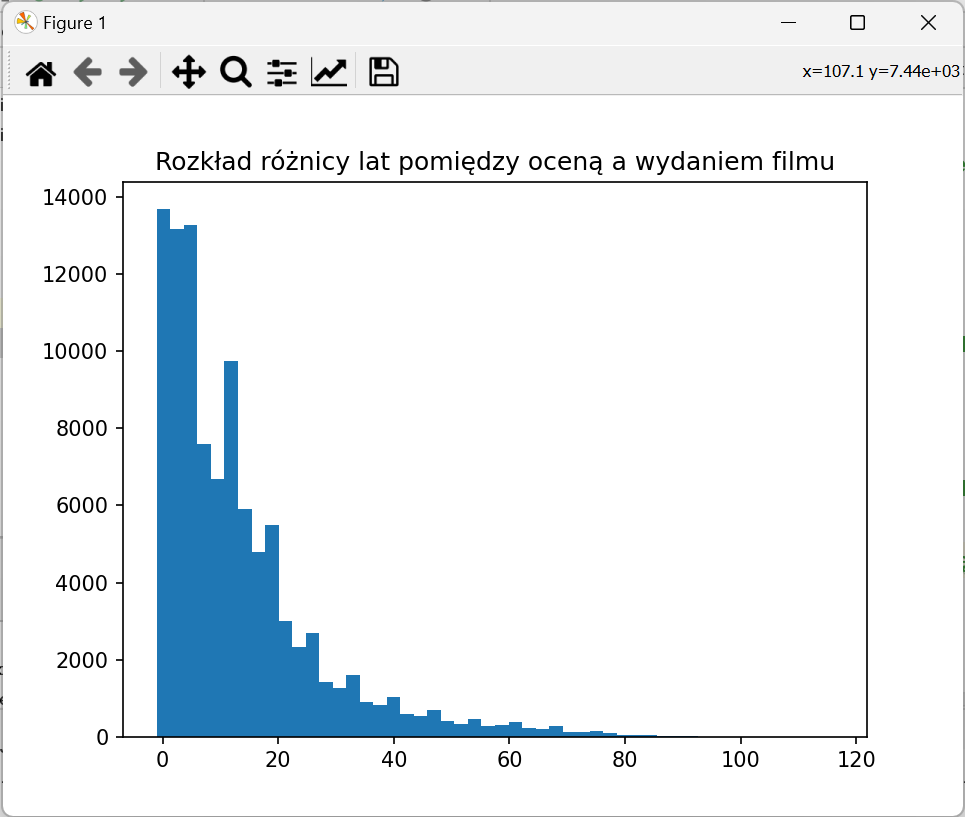
6. Wyświetlenie histogramu
Użyj następującej funkcji:
static void plot_histogram(List<Double> x, List<Double> weights, String title) {
Plot plt = Plot.create();
plt.hist().add(x).weights(weights).bins(50);
plt.title(title);
try {
plt.show();
} catch (IOException e) {
throw new RuntimeException(e);
} catch (PythonExecutionException e) {
throw new RuntimeException(e);
}
}
Przyjmuje ona dwie listy - x to wartości zmiennych na osi X, weights to liczby wystąpień - czyli słupek dla wartości x.get(i) będzie miał wysokość weights.get(i).
- Pobierz listy z wartościami w kolumnach
release_to_rating_yearicount. - Pomiń wiersze, w których
release_to_rating_yearma wartośc NULL. - Wyświetl histogram.
Oczekiwany wynik:
Join MoviesRatingsGenres
Jesteśmy zainteresowani informacjami o ocenach dla gatunków filmów.
1. Załaduj filmy i rozbij tablice z gatunkami na poszczególne rekordy. Następnie dokonaj złączenia z ocenami.
Oczekiwany wynik:
+-------+---------+----------------+----+------+-------+------+-------------------+ |movieId| genre| title|year|userId|movieId|rating| datetime| +-------+---------+----------------+----+------+-------+------+-------------------+ | 1| Fantasy| Toy Story|1995| 1| 1| 4.0|2000-07-30 20:45:03| | 1| Comedy| Toy Story|1995| 1| 1| 4.0|2000-07-30 20:45:03| | 1| Children| Toy Story|1995| 1| 1| 4.0|2000-07-30 20:45:03| | 1|Animation| Toy Story|1995| 1| 1| 4.0|2000-07-30 20:45:03| | 1|Adventure| Toy Story|1995| 1| 1| 4.0|2000-07-30 20:45:03| | 3| Romance|Grumpier Old Men|1995| 1| 3| 4.0|2000-07-30 20:20:47| | 3| Comedy|Grumpier Old Men|1995| 1| 3| 4.0|2000-07-30 20:20:47| | 6| Thriller| Heat|1995| 1| 6| 4.0|2000-07-30 20:37:04| | 6| Crime| Heat|1995| 1| 6| 4.0|2000-07-30 20:37:04| | 6| Action| Heat|1995| 1| 6| 4.0|2000-07-30 20:37:04| +-------+---------+----------------+----+------+-------+------+-------------------+
2. Zgrupuj dane po kolumnie genre i wylicz minimalne, średnie, maksymalne oceny dla każdego gatunku oraz liczbę tych ocen.
+------------------+----------+------------------+----------+----------+ | genre|min_rating| avg_rating|max_rating|rating_cnt| +------------------+----------+------------------+----------+----------+ |(no genres listed)| 0.5|3.4893617021276597| 5.0| 47| | Action| 0.5| 3.447984331646809| 5.0| 30635| | Adventure| 0.5|3.5086089151939075| 5.0| 24161| | Animation| 0.5|3.6299370349170004| 5.0| 6988| | Children| 0.5| 3.412956125108601| 5.0| 9208| | Comedy| 0.5|3.3847207640898267| 5.0| 39053| | Crime| 0.5| 3.658293867274144| 5.0| 16681| | Documentary| 0.5| 3.797785069729286| 5.0| 1219| | Drama| 0.5|3.6561844113718758| 5.0| 41928| | Fantasy| 0.5|3.4910005070136894| 5.0| 11834| | Film-Noir| 0.5| 3.920114942528736| 5.0| 870| | Horror| 0.5| 3.258195034974626| 5.0| 7291| | IMAX| 0.5| 3.618335343787696| 5.0| 4145| | Musical| 0.5|3.5636781053649105| 5.0| 4138| | Mystery| 0.5| 3.632460255407871| 5.0| 7674| | Romance| 0.5|3.5065107040388437| 5.0| 18124| | Sci-Fi| 0.5| 3.455721162210752| 5.0| 17243| | Thriller| 0.5|3.4937055799183425| 5.0| 26452| | War| 0.5| 3.8082938876312| 5.0| 4859| | Western| 0.5| 3.583937823834197| 5.0| 1930| +------------------+----------+------------------+----------+----------+
3. Wyświetl 3 kategorie o najwyższych średnich ocenach oraz największej liczbie ocen.
+-----------+----------+-----------------+----------+----------+ | genre|min_rating| avg_rating|max_rating|rating_cnt| +-----------+----------+-----------------+----------+----------+ | Film-Noir| 0.5|3.920114942528736| 5.0| 870| | War| 0.5| 3.8082938876312| 5.0| 4859| |Documentary| 0.5|3.797785069729286| 5.0| 1219| +-----------+----------+-----------------+----------+----------+
+------+----------+------------------+----------+----------+ | genre|min_rating| avg_rating|max_rating|rating_cnt| +------+----------+------------------+----------+----------+ | Drama| 0.5|3.6561844113718758| 5.0| 41928| |Comedy| 0.5|3.3847207640898267| 5.0| 39053| |Action| 0.5| 3.447984331646809| 5.0| 30635| +------+----------+------------------+----------+----------+
2. Przefiltruj zgrupowane dane pozostawiając tylko te, które mają wartości średnich ocen avg_rating większe niż średnia w całym zbiorze ratings.csv. Uwaga średnia będzie inna, jeżeli zostanie obliczone dla df_ratings (same oceny) i df_mr - połączenie movies i ratings po rozbiciu na gatunki.
+-----------+----------+------------------+----------+----------+ | genre|min_rating| avg_rating|max_rating|rating_cnt| +-----------+----------+------------------+----------+----------+ | Film-Noir| 0.5| 3.920114942528736| 5.0| 870| | War| 0.5| 3.8082938876312| 5.0| 4859| |Documentary| 0.5| 3.797785069729286| 5.0| 1219| | Crime| 0.5| 3.658293867274144| 5.0| 16681| | Drama| 0.5|3.6561844113718758| 5.0| 41928| | Mystery| 0.5| 3.632460255407871| 5.0| 7674| | Animation| 0.5|3.6299370349170004| 5.0| 6988| | IMAX| 0.5| 3.618335343787696| 5.0| 4145| | Western| 0.5| 3.583937823834197| 5.0| 1930| | Musical| 0.5|3.5636781053649105| 5.0| 4138| | Adventure| 0.5|3.5086089151939075| 5.0| 24161| | Romance| 0.5|3.5065107040388437| 5.0| 18124| +-----------+----------+------------------+----------+----------+
3. W zasadzie wykonanie (2) wymaga dwóch kwerend (wywołania subquery). Można to również zakodować w SQL tworząc widoki zbiorów danych.
Przeanalizuj i przetestuj poniższy kod:
df_mr.createOrReplaceTempView("movies_ratings"); df_ratings.createOrReplaceTempView("ratings"); String query = """ SELECT genre, AVG(rating) AS avg_rating, COUNT(rating) FROM movies_ratings GROUP BY genre HAVING AVG(rating) > (SELECT AVG(rating) FROM ratings) ORDER BY avg_rating DESC"""; var df_cat_above_avg = spark.sql(query); df_cat_above_avg.show();
Join UsersTags
1. Wczytaj dane użytkowników do zbioru df_users oraz tagi do df_tags.
df_users.createOrReplaceTempView("users"); //vs. GlobalTempView df_tags.createOrReplaceTempView("tags");
2. Utwórz złączony zbiór za pomocą kwerendy SQL
String query = "..."; Dataset<Row> df_ut = spark.sql(query);
3. Zgrupuj dane po kolumnie email
- Wzynacz listę tagów podczas grupowania za pomocą funkcji
collect_list() - Sklej listę tekstów (wprowadzając separator spacji) za pomocą funkcji
concat_ws()
+--------------------+--------------------+ | email| tags| +--------------------+--------------------+ |amy.mcgrath@movie...|Everything you wa...| |faith.ross@movies...| funny high school| |boris.howard@movi...|funny Highly quot...| |richard.oliver@mo...|music British Rom...| |karen.wilson@movi...|bad Sinbad Comedy...| |melanie.abraham@m...| jackie chan kung fu| ...
Pobierz teksty z kolumny tags do listy i wydukuj
