Next: Loose coupling Up: Design Previous: Coupling Contents
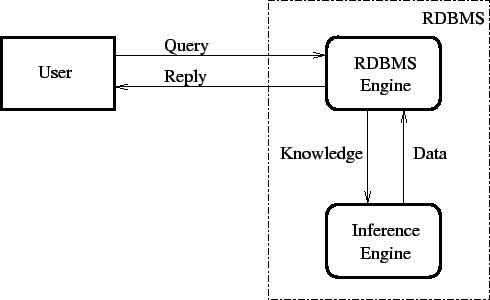
The tight coupling is visualized in Figure 10.1. The inference engine is very closely integrated with the database. When the user issues a query, it is processed by the database, and if necessary, the database launches the inference engine. Then the database generates the reply and sends it back to the user. There are three ways the inference engine can interact with the database in this manner:
The first approach is based on procedure/function extension of the RDBMS. It assumes, that the database has a PSM extension, and a function is capable of calling an external program, which is the inference engine. A Jelly View can be perceived as a database function (PSM).
When such a function acts as the relation in a query, the database calls it and launches the inference engine itself. The inference engine is an external program which is loaded and executed on demand. There are two issues here:
The first issue is quite straightforward. A given database supports such functions or not. If it does not, the inference engine cannot be integrated.
The second issue has two solutions:
For the first item, any modification of the External Matching changes the system catalog, as well. Actually, the External Matching becomes a part of it. Therefore, if a Jelly View is added, this change is made to the system catalog which informs the database that there is a valid function named after that Jelly View. If the function is called by the user query, it launches the inference engine and provides inferred data.
Other solution, using PSM, is to update the system catalog each time the External Matching is changed. If a Jelly View is added in the External Matching, such an operation automatically alters the system catalog informing the database that there is a new function named after that Jelly View. The External Matching can be kept as it was designed previously, providing additionally a routine which can interpret its contents. The routine applies appropriate changes to the system catalog directly, or creates appropriate functions using regular DDL SQL queries from the External Matching data.
Tapping into the query processor of the database requires altering the database server program itself. In order to do this, an access, and permission to modify the source code of particular system have to be obtained. If the database is a free software, then there is no problem with the legal issues, but having a commercial one, obtaining the source code and a permission to modify it, is hardly possible. What is even worse, in such a case, the system will have to be designed for a particular database, which is not a flexible solution at all.
The third way of the tight coupling is the closest integration. The inference engine becomes a part of the database system. It is no longer an external application. As a result its language may be used by a PSM as the native language of the system. Then, the PSM can call the goal directly. In order to achieve such an integration, the database have to provide an extension which allows adding additional languages for building PSM. The other option is altering the source code of the database to make it to support the inference engine language.
In general, the tight integration gives the least amount of overhead for the communication between the inference system and the database system. But, unfortunately, it is much harder to implement, less flexible and almost no portable. In the best, the most flexible, case (a PSM calling the inference engine) there has to be an RDBMS specific routine which converts the External Matching into appropriate PSM at least.
Igor Wojnicki 2005-11-07