Next: Communication methods Up: Design Previous: Tight coupling Contents
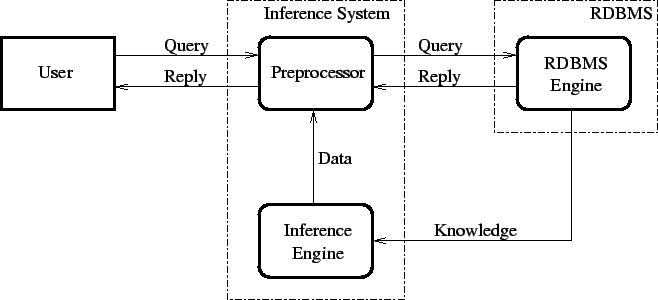
The loose coupling is visualized in Figure 10.2. The inference system is placed, logically, between the user and the database system. The user issues a query, which is intercepted by the inference system. Then, the inference system checks if the query refers to any Jelly Views. If there is such a reference, then it downloads the programs for particular Jelly Views, and it starts the inference engine. When the inferred data is ready, the query is sent to the database, in order to generate the reply. The database reply is based on both the database relations and the inferred data. Then the reply is returned to the user. If there is no reference to a Jelly View, then the query is forwarded to the database directly. The inference system works transparently then: if there is no need for the inference the query and the reply are passed without any modification.
This solution is flexible and applicable to any database system, as long as the communication method between the user and the inference system is the same as the communication method between the inference system and the database. The SQL queries and replies are passed between the user and the RDBMS through some kind of interface (usually network transparent). It could be just plain text communication over the computer network or such a common protocol as the ODBC: Open Database Connectivity.
The inference system becomes a middleware between the user and the database. Having the network nature of the communication, the inference system may run on a machine different than the database system does. Actually, there could be even a farm of the inference systems, working as the middleware between users and the database. The inference systems may be distributed among many physical machines.
There is an important overhead concerning the connection between the inference system and the database. All data, including information about external matching, internal matching, logic program, and inferred data as well, have to travel between these two systems. This communication channel becomes a performance bottleneck of the entire system. There is a trade off, then: flexibility and versatility vs. the communication bottleneck.
There are the following features of the loose coupling:
A more detailed Data Flow Diagram of the loose coupling is given in Figure 10.3. The inference system is named ReDaReS. It is an acronym for: Relational Database Rule System.
When the user issues a query, it is intercepted by ReDaReS. It analyzes the query and confronts it with the External Matching, which is obtained from the database. It checks whether the query refers to a Jelly View or not.
If the query does not refer to any Jelly View, then it is forwarded to the database without any changes. The reply from the database goes to ReDaReS and then it is forwarded to the user. If the query refers to Jelly Views, then the Internal Matching and the Program for particular Jelly Views are brought from the database. Then, the Prolog program is formed, and the inference engine is started.
The inference engine can access extensional knowledge (database relations) on demand, during run-time. Then, the inferred data is generated and sent through the Preprocessor to the database as temporary relations. The user query is rewritten to address the temporary relations instead of the original Jelly Views. The rewritten query is sent to the database. The reply from the database is forwarded to the user.
There are following issues to face:
Igor Wojnicki 2005-11-07
![\includegraphics[width=\textwidth]{pic/arch1}](img241.png)