Table of Contents
Laboratorium 5
1. Konfiguracja Dockera
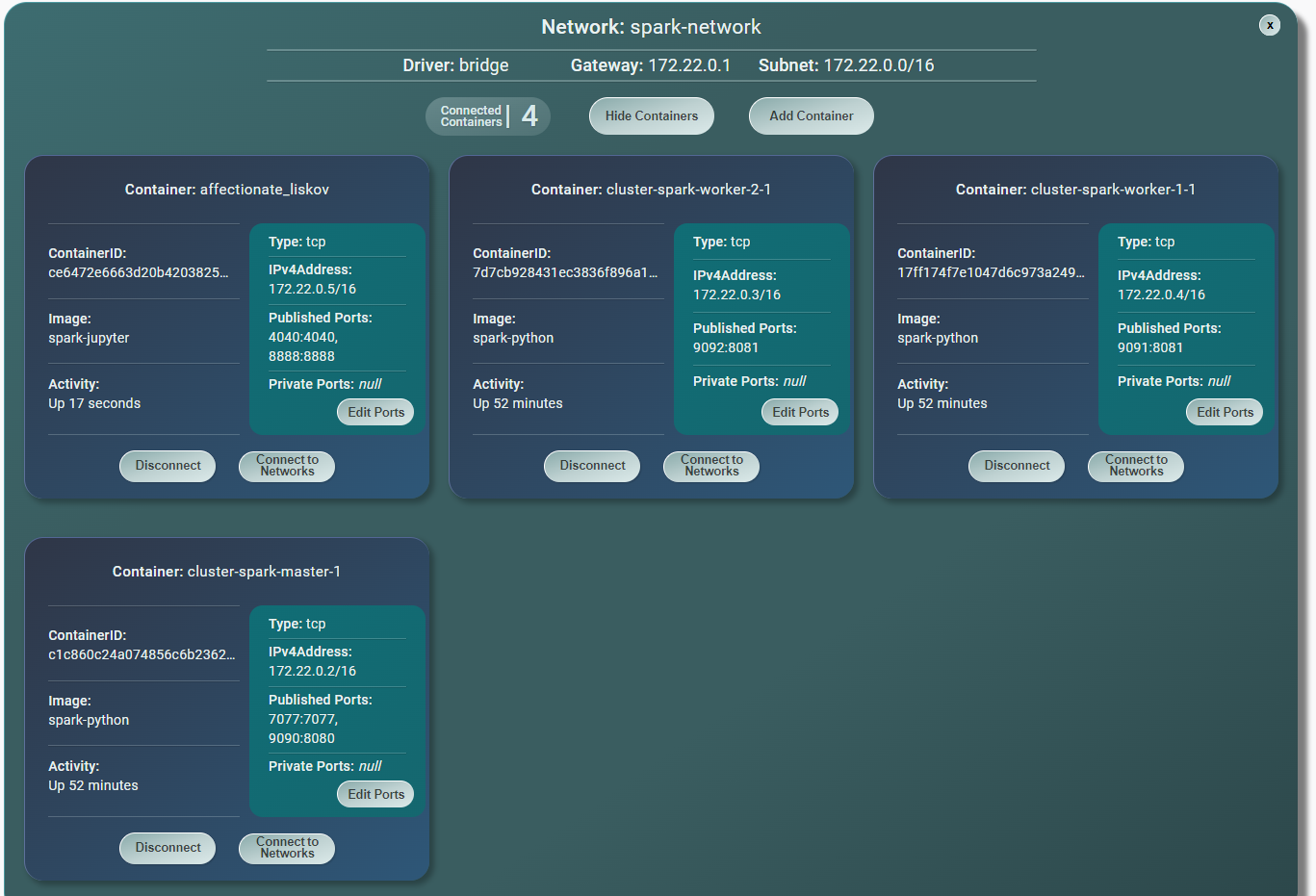
Naszym celem jest zbudowanie konfiguracji jak na rysunku: cztery kontenery połączone wspólną siecią
- master - obraz spark-python
- worker-1 - obraz spark-python
- worker-2 - obraz spark-python
- driver (tu akurat affectionate_liskov) - obraz spark-jupyter
Załóżmy, że pliki są rozmieszczone w katalogach, jak na poniższym diagramie
|-spark-python--+
| | Dockerfile
|
|-spark-jupyter +
| | Dockerfile
|
| -cluster------+
| | docker-compose.yml
|
| data ---------+
| owid-energy-data.csv.gz
Pobierz pliki konfiguracyjne i zbiór danych: spark-jdk17.zip. Następnie rozpakuj w dowolnym katalogu roboczym.
![]() Ze względu na ostrzeżenie podczas budowy obrazów
Ze względu na ostrzeżenie podczas budowy obrazów
Zamień w obu Dockerfile ENV JAVA_HOME /opt/java/openjdk na ENV JAVA_HOME=/opt/java/openjdk
Utwórz sieć spark-network
docker network create -d bridge --subnet=172.22.0.0/16 --gateway=172.22.0.1 spark-network
1.1. Zbuduj obraz spark-python
Przejdź do katalogu spark-python. Powinien w nim znajdować się plik Dockerfile z następującą zawartością:
# image: spark-python
FROM spark:3.5.0-scala2.12-java17-ubuntu
USER root
RUN set -ex; \
apt-get update; \
apt-get install -y sudo python3 python3-pip; \
pip3 cache purge; \
pip3 install pyspark; \
rm -rf /var/lib/apt/lists/*
# RUN echo "spark ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
ENV JAVA_HOME=/opt/java/openjdk
RUN export JAVA_HOME
USER spark
Wydaj komendę:
docker build -f Dockerfile --tag spark-python .
1.2 Zbuduj obraz spark-jupyter
Przejdź do katalogu spark-jupyter. Powinien w nim znajdować się plik Dockerfile z następującą zawartością:
# image: spark-jupyter
FROM spark:3.5.0-scala2.12-java17-ubuntu
USER root
RUN set -ex; \
apt-get update; \
apt-get install -y sudo python3 python3-pip; \
pip3 cache purge; \
pip3 install pyspark==3.5.0 numpy scikit-learn scipy pandas geopandas matplotlib folium mapclassify plotly jupyterlab; \
apt-get install -y pandoc; \
rm -rf /var/lib/apt/lists/*
RUN echo "spark ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
ENV JAVA_HOME=/opt/java/openjdk
RUN export JAVA_HOME
USER spark
Wydaj komendę:
docker build -f Dockerfile --tag spark-jupyter .
Obraz zawiera zbiór bibliotek ogólnego zastosowania języka Python do eksploracji danych, wizualizacji i uczenie maszynowego:
- bibliotekę pyspark
- typowe biblioteki uczenia maszynowego (ale bez tensorflow)
- jupyter-lab (wsparcie dla notatników)
- poandoc i instalację latexa (po załadowaniu notatnika możliwy jest wydruk w formacjie PDF z zawijaniem długich linii
Jak uruchomić - opis w sekcji 3.1
1.3 Uruchomienie klastra
W katalogu cluster powinien znaleźć się plik docker-compose.yml z następującą zawartością
services:
spark-master:
image: spark-python
command: /opt/spark/bin/spark-class org.apache.spark.deploy.master.Master
networks:
spark-network:
ipv4_address: 172.22.0.2
# volumes:
# - ".:/opt/spark/work-dir"
ports:
- "9090:8080"
- "7077:7077"
#- "4040:4040"
#environment:
#SPARK_DAEMON_MEMORY: 4g
spark-worker-1:
image: spark-python
command: /opt/spark/bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
depends_on:
- spark-master
networks:
spark-network:
ports:
- "9091:8081"
# ipv4_address: 172.22.0.3
volumes:
- ".:/opt/spark/work-dir"
environment:
SPARK_MODE: worker
SPARK_WORKER_CORES: 4
#SPARK_WORKER_MEMORY: 4g
SPARK_MASTER_URL: spark://spark-master:7077
spark-worker-2:
image: spark-python
command: /opt/spark/bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
depends_on:
- spark-master
networks:
spark-network:
# ipv4_address: 172.22.0.4
ports:
- "9092:8081"
volumes:
- ".:/opt/spark/work-dir"
environment:
SPARK_MODE: worker
SPARK_WORKER_CORES: 4
#SPARK_WORKER_MEMORY: 4g
SPARK_MASTER_URL: spark://spark-master:7077
networks:
spark-network:
external: true
ipam:
config:
- subnet: 172.22.0.0/16
- Klaster zawiera trzy węzły:
masteri dwa węzły obliczenioweworkerpołączone wspólną siecią spark-network - Dla węzłów
workerzamontowany jest lokalny katalog - Udostępnione są porty, za pomocą których można monitorować stan węzłów (WebUI)
Przejdź do katalogu cluster i wydaj komendę:
docker-compose up
W tym momencie węzły obliczeniowe powinny uruchomić się. Po kilkudziesięciu sekundach dostępne będą ich interfejsy webowe:
- MasterUI http://localhost:9090/
- WorkerUI (worker-1) http://localhost:9091/
- WorkerUI (worker-1) http://localhost:9092/
1.4 Uruchomienie węzła spark-jupyter
Kontener będzie uruchamiany za pomocą polecenia:
docker run -it --rm -v ".:/opt/spark/work-dir" -p 4040:4040 -p 8888:8888 --network spark-network spark-jupyter /bin/bash
- Kontener jest dołączony do sieci
spark-network. Dzięki temu będzie mógł komunikować się z węzłami obliczeniowymi - Mapowanie portów 4040:4040 pozwoli na dostęp do WebUI
- Porty 8888:8888 zostaną wykorzystane przez jupyter-lab
- Montowany jest bieżący katalog
- W momencie uruchomienia wołany jest shell
2 Java
2.1 PiComputeApp
1. Dodaj kod klasy do projektu i wprowadź odpowiednie wywołanie w funkcji Main.main()
public class PiComputeApp implements Serializable { private static long counter = 0; public static void main(String[] args) { int slices=100; int n = 1000_000 * slices; System.out.printf("Table of %d elements will be divided into %d partitions.\n" + "Each partition will be processed as separate task\n",n,slices); long t0 = System.currentTimeMillis(); SparkSession spark = SparkSession .builder() .appName("Spark Pi") .master("local[*]") .getOrCreate(); SparkContext sparkContext = spark.sparkContext(); JavaSparkContext ctx = new JavaSparkContext(sparkContext); long t1 = System.currentTimeMillis(); System.out.println("Session initialized in " + (t1 - t0) + " ms"); List<Integer> l = new ArrayList<>(n); for (int i = 0; i < n; i++) { l.add(i); } JavaRDD<Integer> dataSet = ctx.parallelize(l, slices); long t2 = System.currentTimeMillis(); System.out.println("Initial dataframe built in " + (t2 - t1) + " ms"); final int count = dataSet.map(integer -> { double x = Math.random() * 2 - 1; double y = Math.random() * 2 - 1; return (x * x + y * y < 1) ? 1 : 0; }).reduce((a, b) -> a + b); long t3 = System.currentTimeMillis(); System.out.println("Map-reduce time " + (t3 - t2) + " ms"); System.out.println("Pi is roughly " + 4.0 * count / n); spark.stop(); } }
Aplikacja tworzy listę 100_000_000 liczb całkowitych i rozdziela je na 100 partycji. Partycje te są przetwarzane równolegle przez lokalnie działające wątki. Podczas operacji map losowane są dwie liczby x oraz y i zwracany wynik
- 1 - jeżeli (x,y) mieści się w ćwiartce okręgu
- 0 w przeciwnym przypadku.
Po zsumowaniu i podzieleniu przez liczbę punktów otrzymamy przybliżenie liczby $pi$.
2. Dodaj artefakt. Na przykład będzie miał nazwę pi_compute.jar
W InteliJ:
- Wybierz:Project Structure→Artifacts→JAR from module with dependencies
- Nie kopiuj bibliotek do pliku wyjściowego
*.jar. W zakładce Output Layout zaznacz wszystkie biblioteki Mavena i usuń je zostawiając sam artefakt. W ten sposób unikniesz przesyłania do serwera Fat JAR/Uber JAR - Manipulując opcjami można ustawić katalog wyjściowy i nazwę pliku *.jar.
- Zbuduj artefakt
3. W tym przypadku możesz przejść do katalogu wyjściowego, gdzie pojawił się artefakt i uruchomić kontener spark-jupyter
docker run -it --rm -v ".:/opt/spark/work-dir" -p 4040:4040 -p 8888:8888 --network spark-network spark-jupyter /bin/bash
Po uruchomieniu kontenera pojawi się znak zachęty bash. Wydaj komendę ls. Artefakt powinien być widoczny
3. Aplikacja zostanie uruchomiona poprzez przesłanie artefaktu do środowiska spark, za pomocą polecenia spark-submit (wewnątrz bash na dockerze):
/opt/spark/bin/spark-submit --driver-memory 4g --executor-memory 4g --class org.example.Main --master spark://172.22.0.2:7077 pi_compute.jar
4. W tym momencie rozpocznie się wykonywanie aplikacji. Wyznaczona wartość będzie wypisana na konsoli. Możliwe jest także monitorowanie przebiegu aplikacji pod adresem http://localhost:4040
- Job (zadanie) - wysokopoziomowe obliczenie uruchomione w wyniku takiej akcji, jak
map()lubreduce(). Podczas wykonania akcji Spark uruchamia job. - Stage (etap) - jest kolekcją podzadań, które mogą być wykonywane równolegle, wszystkie przeprowadzają to samo obliczenie, ale na innej partycji danych. Czyli etap stage reprezentuje krok w planie wykonania zadania. Etapy są tworzone na podstawie transformacji danych, a zwłaszcza zależnościa związanymi z przesyłaniem danych pomiędzy węzłami obliczeniowymi.
- Executor (wykonawca) - w tym przypadku jednym wykonawcą jest driver.
5. Umieść w sprawozdaniu fragmenty zrzutów ekranu pokazujące działanie wykonawcy Sparka (konsoli i DriverUI)
2.2 PiComputeAppDistributed
1. Wprowadź minimalną zmianę w kodzie aplikacji. Różnicą jest wskazanie adresu węzła Master.
SparkSession spark = SparkSession .builder() .appName("Spark Pi Distributed") .master("spark://172.22.0.2:7077") .getOrCreate();
2. Zadbaj, aby kod był wywoływany z Main.main(), zbuduj artefakt.
3. Prześlij do wykonania z a pomocą spark-submit (w bash w konsoli kontenera spark-jupyter)
4. Zamieść w spawozdaniu zrzuty WebUI węzłów Master i Worker(ów) wskazujących, że aplikacja była przez nie wykonywana. Możesz też dodać wykres Gantta z wykonywanych zadań (z DriverUI - port 4040, opcja timeline).
![]() 2026 W przypadku problemów zmniejsz wartość
2026 W przypadku problemów zmniejsz wartość executor memory, np. na 2g
2.3 LoadDistributedDataset
Załadujemy zbiór danych do Sparka. Musi być on dostępny dla węzłów
- Driver
- Worker
W przemysłowym zastosowaniu byłby widoczny np. na rozproszonym systemie plików. W naszym przypadku skorzystamy z montowanych wolumenów Dockera (czyli będzie widoczny lokalnie).
Kontener wykonujący program węzła driver (spark-jupyter) będzie uruchamiany z katalogu cluster (zawierającym podkatalog data).
1. Dodaj kod klasy dla nowej aplikacji oraz wywołaj ją w Main.main()
public class LoadDistributedDataset { public static void main(String[] args) { SparkSession spark = SparkSession.builder() .appName("LoadDatasetDistributed") .master("spark://172.22.0.2:7077") .getOrCreate(); Dataset<Row> df = spark.read().format("csv") .option("header", "true") .option("inferschema","true") .load("data/owid-energy-data.csv.gz"); df.show(5); // To raczej zakomentuj... df=df.select("country","year","population","electricity_demand").where("country like \'Po%\' AND year >= 2000"); df.show(5); df.printSchema(); } }
2. Skonfiguruj i zbuduj nowy artefakt (np. distributed_dataset.jar)
3. Przekopiuj ręcznie artefakt do katalogu cluster
4. Przejdź do katalogu cluster i uruchom tam kontener
docker run -it --rm -v ".:/opt/spark/work-dir" -p 4040:4040 -p 8888:8888 --network spark-network spark-jupyter /bin/bash
Następnie sprawdź, czy artefakt i podkatalog data są widoczne
5. Wykonaj spark-submit, aby rozpocząć wykonywanie aplikacji
/opt/spark/bin/spark-submit --driver-memory 4g --executor-memory 4g --class org.example.Main --master spark://172.22.0.2:7077 distributed-dataset.jar
6. Oczekiwany efekt:
- widoczna uruchomiona lub wykonana aplikacja w WebUI węzłów Master i Worker
- Wydrukowana ramka na konsoli (węzła driver w Dockerze)
+-------+----+----------+------------------+ |country|year|population|electricity_demand| +-------+----+----------+------------------+ | Poland|2000| 38504432| 136.81| | Poland|2001| 38662860| 136.99| | Poland|2002| 38647476| 135.42| | Poland|2003| 38621536| 139.85| | Poland|2004| 38596040| 142.97| +-------+----+----------+------------------+ only showing top 5 rows root |-- country: string (nullable = true) |-- year: integer (nullable = true) |-- population: long (nullable = true) |-- electricity_demand: double (nullable = true)
3 PySpark + Jupyter
Spróbujemy powtórzyć te kroki w środowisku Jupyter korzystając z biblioteki PySpark.
PySpark zapewnia interfejs w języku Python do platformy Spark. Aby go użyć - biblioteka PySpark musi być zainstalowana na wszystkich węzałach (co było uwzględnione przy budowie obrazów). Wewnętrznie korzysta z biblioteki Py4J pozwalającej na dostęp do obiektów Java (w maszynie wirtualnej JVM) z poziomu kodu w języku Python.
3.1 Uruchomienie jupyter-lab
1. Uruchom obraz spark-jupyter w katalogu cluster
docker run -it --rm -v ".:/opt/spark/work-dir" -p 4040:4040 -p 8888:8888 --network spark-network spark-jupyter /bin/bash
2. Wydaj polecenie
sudo --preserve-env jupyter-lab --ip=0.0.0.0 --allow-root --IdentityProvider.token='pyspark'
3. W przeglądarce otwórz link http://localhost:8888/?token=pyspark (albo bez parametru token i wpisz pyspark w formularzu)
Obraz spark-jupyter zawiera podstawowe biblioteki do realizacji zadań uczenia maszynowego. Można go wykorzystać na innych zajęciach.
![]() 2026 Zmieniła się defaultowa wersja pyspark. W pliku Dockerfile dla obrazu spark-jupyter nalezy ustalić wersję na 3.5.0:
2026 Zmieniła się defaultowa wersja pyspark. W pliku Dockerfile dla obrazu spark-jupyter nalezy ustalić wersję na 3.5.0:
pip3 install pyspark==3.5.0 numpy scikit-learn scipy pandas geopandas matplotlib folium mapclassify plotly jupyterlab;
3.2 Wyznaczanie liczby PI
1. Utwórz notatnik PiCompute i wprowadź w nim kod aplikacji (komórki) do wyznaczania liczby $\pi$
import pyspark from random import random from operator import add from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("PiCompute").master("spark://172.22.0.2:7077").getOrCreate()
Tu otwórz WebUI modułu driver na localhost
partitions = 100 n = 1_000_000 * partitions def f(_: int) -> float: x = random() * 2 - 1 y = random() * 2 - 1 return 1 if x ** 2 + y ** 2 <= 1 else 0 count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add) print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()
2. Możesz uruchamiać interaktywnie kolejne komórki i monitorować działanie aplikacji w WebUI. Do momentu jawnego zakończenia sesji, będzie ona aktywna.
3.3 LoadEnergyDataset
1. Utwórz notatnik i wprowadź w nim kod:
import pyspark from random import random from operator import add from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("LoadEnergyDataset").master("spark://172.22.0.2:7077").getOrCreate()
2. załaduj dane
df = spark.read.format("csv").option("header", "true").option("inferschema","true").load("data/owid-energy-data.csv.gz")
Możesz spróbować je wyświetlić
df.show(5,70)
… ale raczej skasuj wyjście komórki
3. Wybierzemy dane do wyświetlenia
df2 = df.select("country","year","population","electricity_demand").where("country like \'Po%\' AND year >= 2000")
I wyświetlimy je:
df2.show(5) df2.printSchema()
Zauważ, że ze względu na lazy evaluation dopiero ta komórka powoduje aktywność Sparka
3. Wybierzmy podzbiór danych z Polski z interesującymi nas niepustymi wartościami
df_pl = df.select('year','population','electricity_demand').where(("country == 'Poland' AND electricity_demand IS NOT NULL")) df_pl.show()
Wykresy
Przekonwertujemy dane do postaci list
import matplotlib.pyplot as plt df_pl = df_pl.orderBy('year') y = df_pl.select('year').rdd.flatMap(lambda x: x).collect() pop = df_pl.select('population').rdd.flatMap(lambda x: x).collect() dem = df_pl.select('electricity_demand').rdd.flatMap(lambda x: x).collect()
oraz wyświetlimy je…
plt.plot(y,pop) plt.xlabel('year') plt.ylabel('population') plt.title('Population vs. year') plt.show()
plt.plot(y,dem,label='demand') plt.xlabel('year') plt.ylabel('demand') plt.title('Demand vs. year') plt.show()
plt.scatter(pop,dem) plt.xlabel('population') plt.ylabel('demand') plt.title('Demand vs. population') plt.show()
Regresja liniowa
Dla których zależności można zastosować regresję?
1. Dodaj kod:
from pyspark.ml.regression import LinearRegression from pyspark.ml.feature import VectorAssembler va=VectorAssembler().setInputCols(["year"]).setOutputCol("features") df_plf = va.transform(df_pl) df_plf.show(5) lr = LinearRegression()\ .setMaxIter(10)\ .setRegParam(3.0)\ .setElasticNetParam(0.5)\ .setFeaturesCol("features")\ .setLabelCol("electricity_demand") model = lr.fit(df_plf)
2. Wyświetl metryki oraz równanie regresji
print(f'RMSE: {model.summary.rootMeanSquaredError}') print(f'r2: {model.summary.r2}') print(f'iterations: {model.summary.totalIterations}') print(f'demand = {model.coefficients}*year {"+" if model.intercept > 0 else ""} {model.intercept}')
3. Wyświetl wykresy
import numpy as np # from pyspark.sql.types import StructType, StructField, DoubleType from pyspark.ml.linalg import Vectors xmin = np.min(y) xmax = np.max(y) xx = np.linspace(xmin-1,xmax+1,100) yy = [model.predict(Vectors.dense([x])) for x in xx] plt.scatter(y,dem,label='demand') plt.plot(xx,yy,label='fitted function',c='orange') plt.legend() plt.title('Electric energy demand in years') plt.show()
4. Zakończ sesję
Przed zakończeniem sesji obejrzyj DriverUI (localhost:4040) a zwłaszcza diagramy pokazujące konstrukcję i statystyki kwerend w zakładce SQL / Dataframe – otwórz linki do kwerend.
spark.stop()
3.4 TODO - regresja dla Chin
Przeprowadź taką samą analizę dla Chin, ale spróbuj znaleźć zależność pomiędzy liczbą ludności, a zapotrzebowaniem na energię (która w przypadku Chin jest raczej widoczna).
- Zapisz notatnik jako HTML
- Następnie wybierz opcję drukuj do PDF. Możesz przy okazji wybrać niestandardowe skalowanie i zmniejszyć skalę. Wtedy za szerokie tabelki zmieszczą się na stronie (przynajmniej niektóre).
- Prześlij plik PDF razem ze sprawozdaniem
