Table of Contents
Laboratorium 8 - regresja logistyczna
Celem jest budowa modelu regresji logistycznej pozwalającej przewidywać, czy dany student zdał egzamin z języka C++ w pierwszym terminie. Implementujemy oprogramowanie w języku Java.
Dla przypomnienia
- Regresja logistyczna jest metodą klasyfikacji binarnej.
- Posługuje się pojęciem szansy $o=\frac{p}{1-p}$
- Modeluje powiązanie prawdopodobieństwa etykiety 1 z modelem liniowym jako $logit(p) = ln(\frac{p}{1-p})=w^T x$
- Po przekształceniach: prawdopodobieństwo etykiety 1 opisane jest wzorem $p=\frac{1}{1+exp(-w^T x)}$
Patrz: wykład 4
Zbiory danych
- egzamin-cpp.csv - poddane anonimizacji wyniki zaliczeń/egzaminu z C i C++ w 2016 roku
- grid.csv - kombinacje ocen
egzamin-cpp.csv
ImieNazwisko;OcenaC;DataC;OcenaCpp;Egzamin Dqhoil Dhxpluj;3.5;2016-01-14;4;3 Bhnhgpxj Lwjmq;4.5;2016-01-14;4;3 Wkgjnerme Djfbw;4;2016-01-20;3;2 Sredvmuwt Tcimknl;4.5;2016-01-20;4.5;3.5 Tiowe Bqoilnqbrx;4;2016-01-14;4.5;3 Bvaysqv Wuyih;3.5;2016-01-14;5;3 Jjoaxp Ktapcy;5;2016-01-20;4;3.5
grid.csv
ImieNazwisko,OcenaC,DataC,OcenaCpp 'Xxxxx Yyyyyy',3,2016-01-17,2 'Xxxxx Yyyyyy',3,2016-01-17,3 'Xxxxx Yyyyyy',3,2016-01-17,3.5 'Xxxxx Yyyyyy',3,2016-01-17,4 'Xxxxx Yyyyyy',3,2016-01-17,4.5 'Xxxxx Yyyyyy',3,2016-01-17,5 'Xxxxx Yyyyyy',3.5,2016-01-17,2 'Xxxxx Yyyyyy',3.5,2016-01-17,3 'Xxxxx Yyyyyy',3.5,2016-01-17,3.5 'Xxxxx Yyyyyy',3.5,2016-01-17,4 'Xxxxx Yyyyyy',3.5,2016-01-17,4.5 'Xxxxx Yyyyyy',3.5,2016-01-17,5 'Xxxxx Yyyyyy',4,2016-01-17,2 'Xxxxx Yyyyyy',4,2016-01-17,3 'Xxxxx Yyyyyy',4,2016-01-17,3.5 'Xxxxx Yyyyyy',4,2016-01-17,4 'Xxxxx Yyyyyy',4,2016-01-17,4.5 'Xxxxx Yyyyyy',4,2016-01-17,5 'Xxxxx Yyyyyy',4.5,2016-01-17,2 'Xxxxx Yyyyyy',4.5,2016-01-17,3 'Xxxxx Yyyyyy',4.5,2016-01-17,3.5 'Xxxxx Yyyyyy',4.5,2016-01-17,4 'Xxxxx Yyyyyy',4.5,2016-01-17,4.5 'Xxxxx Yyyyyy',4.5,2016-01-17,5 'Xxxxx Yyyyyy',5,2016-01-17,2 'Xxxxx Yyyyyy',5,2016-01-17,3 'Xxxxx Yyyyyy',5,2016-01-17,3.5 'Xxxxx Yyyyyy',5,2016-01-17,4 'Xxxxx Yyyyyy',5,2016-01-17,4.5 'Xxxxx Yyyyyy',5,2016-01-17,5
1. Ładowanie danych i przetwarzanie wstępne
1. Utwórz sesję Sparka i załaduj zbiór danych. Wyświetl zawartość i schemat
SparkSession spark = SparkSession.builder() .appName("LogisticRegressionOnExam") .master("local") .getOrCreate(); ...
root |-- ImieNazwisko: string (nullable = true) |-- OcenaC: double (nullable = true) |-- DataC: date (nullable = true) |-- OcenaCpp: double (nullable = true) |-- Egzamin: double (nullable = true)
2. Regresja logistyczna wymaga, aby atrybutów wejściowe były typu numerycznego. Jest też metodą klasyfikacji binarnej (etykiety powinny mieć wartości 0 i 1)
- przekonwertuj datę za pomocą funkcji
unix_timestamp- nadaj nowej kolumnie nazwętimestamp - Dodaj kolumnę
Wynikbędącą wynikiem testu, czyEgzamin>=3.0- użyj funkcji SQL IF()
+-----------------+------+----------+--------+-------+----------+-----+ | ImieNazwisko|OcenaC| DataC|OcenaCpp|Egzamin| timestamp|Wynik| +-----------------+------+----------+--------+-------+----------+-----+ | Dqhoil Dhxpluj| 3.5|2016-01-14| 4.0| 3.0|1452726000| 1| | Bhnhgpxj Lwjmq| 4.5|2016-01-14| 4.0| 3.0|1452726000| 1| | Wkgjnerme Djfbw| 4.0|2016-01-20| 3.0| 2.0|1453244400| 0| |Sredvmuwt Tcimknl| 4.5|2016-01-20| 4.5| 3.5|1453244400| 1| | Tiowe Bqoilnqbrx| 4.0|2016-01-14| 4.5| 3.0|1452726000| 1| | Bvaysqv Wuyih| 3.5|2016-01-14| 5.0| 3.0|1452726000| 1| | Jjoaxp Ktapcy| 5.0|2016-01-20| 4.0| 3.5|1453244400| 1| | Mkengbtw Aainhh| 3.5|2016-01-20| 3.0| 2.0|1453244400| 0| | Fbffjb Muupwshu| 4.0|2016-01-14| 5.0| 4.0|1452726000| 1| | Yahwfyp Bvnlsig| 5.0|2016-01-14| 4.5| 4.0|1452726000| 1| +-----------------+------+----------+--------+-------+----------+-----+
2. LogisticRegressionAnalysis - analiza działania algorytmu
2.1 Budowa modelu i interpretacja współczynników
1. Skonfiguruj algorytm i zbuduj model
LogisticRegression lr = new LogisticRegression() .setMaxIter(100) .setRegParam(0.1) .setElasticNetParam(0) .setFeaturesCol("features") .setLabelCol("Wynik"); LogisticRegressionModel lrModel = lr.fit(df);
2. Napisz kod, który drukuje równanie regresji logistycznej
Oczekiwany wynik:
logit(zdal) = 0.719097*OcenaC + -0.000000*timestamp + 0.993461*OcenaCPP + 118.340611
3. Zinterpretuj współczynniki równania regresji (napisz kod lub zamieść wykonane obliczenia). Pamiętaj, że timestamp jest wyrażony w sekundach.
Poniższe wyniki były wygenerowane programowo. W praktyce wynik nie zależy od daty…
Wzrost OcenaC o 1 zwiększa logit o 0.719097, a szanse zdania razy 2.052578 czyli o 105.257821% Wzrost DataC o 1 dzień zwiększa logit o -0.000000,a szanse zdania razy 0.992648 czyli o -0.735167% Wzrost OcenaCPP o 1 zwiększa logit o 0.719097,a szanse zdania razy 2.700564 czyli o 170.056381%
2.2 Predykcja i jej wyniki
1. Wywołaj funkcję predykcji i wyświetl dane…
Dataset<Row> df_with_predictions=lrModel.transform(df_trans); var df_predictions = df_with_predictions .select("features","rawPrediction","probability","prediction");
2. Napisz funkcję, która wyświetli informacje dotyczące predykcji
private static void analyzePredictions(Dataset<Row> dfPredictions,LogisticRegressionModel lrModel) { dfPredictions.foreach(new ForeachFunction<Row>() { ... }); }
Wewnątrz:
- oblicz wartośc
logitjako iloczyn skalarny współczynników i cech powiększony olrModel.intercept() - Oblicz prawdopodobieństwo P(0) i P(1) z odpowiedniego wzoru - wykorzystując wartośc logit
- Wyświetl i porównaj wartości
rawPredictioniprawdopodobieństwa - Wyświetl prawdopodobieństwo wybranej przez klasyfikator etykiety - czyli większe z prawdopodobieństw
- Funkcja
row.getAs(String)zwraca element w danej kolumnie. Użyj też funkcjiVector.argmax()
2.3 Dodaj do zbioru prawdopodobieństwo wybranej etykiety
Zadaniem jest dodanie do zbioru danych kolumny prob zawierającej wartość prawdopodobieństwa przypisanego etykiecie. Musimy wyodrębnić je z atrybutu probability. W tym celu użyjemy mechanizmu User Defined Function (UDF). UDF to funkcja użytkownika rozszerzająca interfejs funkcjonalny Sparka. Funkcja musi zostać zarejestrowana w sesji.
1. Dodaj klasę zagnieżdżoną:
static class MaxVectorElement implements UDF1<Vector,Double> { @Override public Double call(Vector vector) throws Exception { return // największy element wektora - czyli o indeksie vector.argmax() } }
2. Zarejestruj funkcję (zazwyczaj bezpośrednio po utworzeniu sesji)
spark.udf().register( "max_vector_element",new MaxVectorElement(),DataTypes.DoubleType);
Alternatywnym rozwiązaniem może być rejestracja funkcji jako wyrażenia lambda, bez deklarowania klasy
UDF1<Vector,Double> mve = v-> ???; spark.udf().register( "max_vector_element_alt",mve,DataTypes.DoubleType);
3. Przekonwertuj zbiór z wynikami predykcji. Usuń kolumny typu features i rawPredictions Dodaj kolumnę prob z rezultatami wywołania UDF
.withColumn("prob",callUDF("max_vector_element",col("probability")))...
Oczekiwany wynik:
+-----------------+------+----------+--------+-------+----------+-----+----------+------------------+ | ImieNazwisko|OcenaC| DataC|OcenaCpp|Egzamin| timestamp|Wynik|prediction| prob| +-----------------+------+----------+--------+-------+----------+-----+----------+------------------+ | Dqhoil Dhxpluj| 3.5|2016-01-14| 4.0| 3.0|1452726000| 1| 1.0|0.6822140478017863| | Bhnhgpxj Lwjmq| 4.5|2016-01-14| 4.0| 3.0|1452726000| 1| 1.0| 0.815034643789244| | Wkgjnerme Djfbw| 4.0|2016-01-20| 3.0| 2.0|1453244400| 0| 1.0|0.5214319094648453| |Sredvmuwt Tcimknl| 4.5|2016-01-20| 4.5| 3.5|1453244400| 1| 1.0|0.8738590749460415| | Tiowe Bqoilnqbrx| 4.0|2016-01-14| 4.5| 3.0|1452726000| 1| 1.0| 0.834828781680339| +-----------------+------+----------+--------+-------+----------+-----+----------+------------------+
2.4 Zapisz zbiór z wynikami
df_predictions = df_predictions.repartition(1); df_predictions.write() .format("csv") .option("header", true) .option("delimiter",",") .mode(SaveMode.Overwrite) .save("????/egzamin-with-classification.csv");
Instrukcja df_predictions = df_predictions.repartition(1); jest opcjonalna. Jaka będzie postać wyjścia, kiedy zmienimy argument repartition - np. ustawimy 5.
3. LogisticRegressionScores - ocena wyników
Napisz funkcję trainAndTest, która:
- dokona podziału na zbiór treningowy i testowy
- skonfiguruje algorytm
- i przeprowadzi uczenie na zbiorze treningowym
static LogisticRegressionModel trainAndTest(Dataset<Row> df){ int splitSeed = 123; Dataset<Row>[] splits = df.randomSplit(new double[]{0.7, 0.3},splitSeed); Dataset<Row> df_train = splits[0]; Dataset<Row> df_test = splits[1]; LogisticRegression lr = new LogisticRegression() .setMaxIter(20) .setRegParam(0.1) .setFeaturesCol("features") .setLabelCol("Wynik"); LogisticRegressionModel lrModel = lr.fit(df_train); ... return lrModel; }
3.1 Analiza informacji zebranych w training summary
BinaryLogisticRegressionTrainingSummary trainingSummary = lrModel.binarySummary();
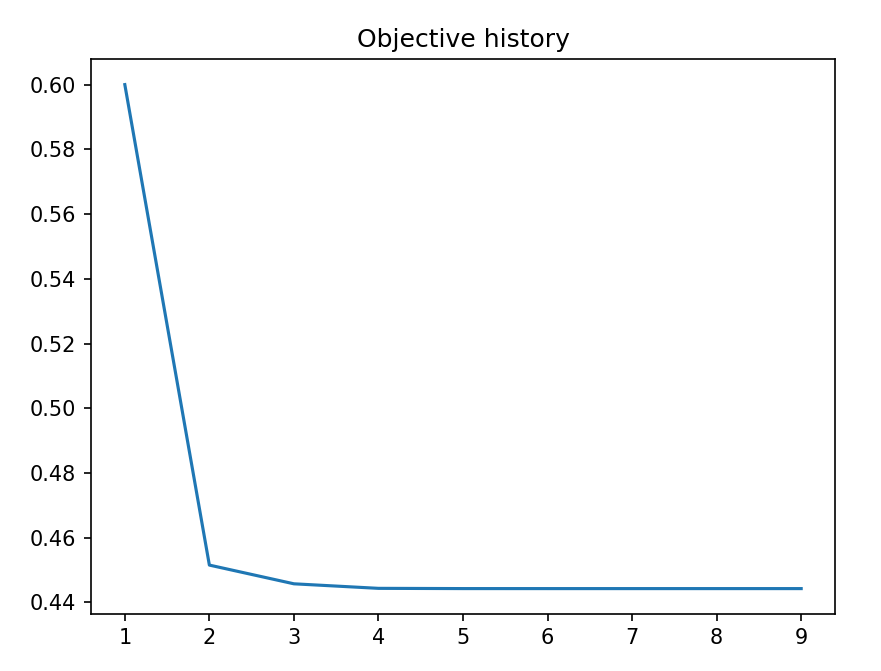
1. Pobierz historię objective history i wyświetl jej wykres. Napisz odpowiednią funkcję do wyświetlania wykresu plotObjectiveHistory()
double[] objectiveHistory = trainingSummary.objectiveHistory(); plotObjectiveHistory(objectiveHistory);
Oczekiwany wynik:
2. Pobierz informacje o krzywej ROC. Możesz o niej przeczytać tu: Wykład 4, slajdy 24-27
Dataset<Row> roc = trainingSummary.roc(); roc.show();
+--------------------+-------------------+ | FPR| TPR| +--------------------+-------------------+ | 0.0| 0.0| | 0.0|0.07692307692307693| | 0.0|0.09615384615384616| | 0.0|0.15384615384615385| | 0.0|0.21153846153846154| | 0.0|0.23076923076923078| | 0.0| 0.3076923076923077| | 0.0|0.34615384615384615| | 0.0|0.38461538461538464| | 0.0| 0.4230769230769231| | 0.0| 0.4807692307692308| | 0.0| 0.5| | 0.0| 0.5192307692307693| | 0.0| 0.5576923076923077| | 0.0| 0.5961538461538461| |0.047619047619047616| 0.5961538461538461| |0.047619047619047616| 0.6153846153846154| |0.047619047619047616| 0.6730769230769231| | 0.09523809523809523| 0.6730769230769231| | 0.14285714285714285| 0.6923076923076923| +--------------------+-------------------+
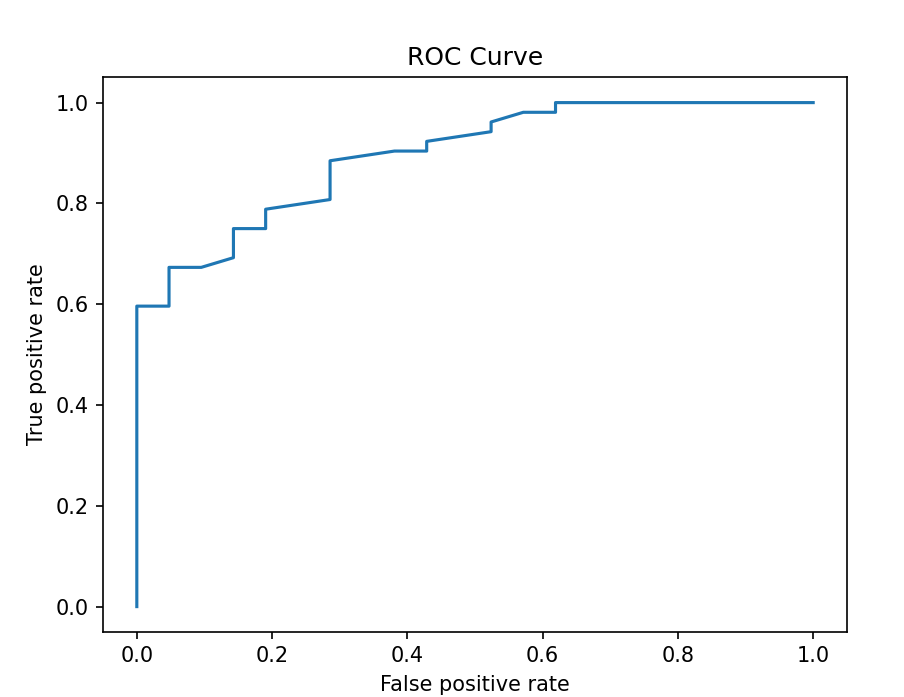
3. Wyświetl wykres ROC. Napisz odpowiednią funkcję
static void plotROC(Dataset<Row> roc)
Oczekiwany wynik:
3. Wyświetl miary:
- Accuracy
- FPR
- TPR
- Precision
- Recall
- F-measure
3.2 Dobór progu prawdopodobieństwa
Krzywą ROC można wykorzystać do doboru progu prawdopodobieństwa. Patrz Wykład 4 slajd 27
1. Dobierzemy próg według miary F-measure. To będzie gdzieś tu:
Dataset<Row> df_fmeasures = trainingSummary.fMeasureByThreshold(); df_fmeasures.offset(35).show();
+-------------------+------------------+ | threshold| F-Measure| +-------------------+------------------+ | 0.4627032508959811|0.8869565217391304| | 0.4382847817892507|0.8793103448275861| | 0.4034706528697256| 0.888888888888889| | 0.3858997834933381|0.8813559322033898| | 0.3461380134069699| 0.859504132231405| | 0.3143853597224281|0.8524590163934427| |0.19135299955580787|0.8455284552845529| | 0.1472470120383692|0.8387096774193548| |0.13010893832947723| 0.832| +-------------------+------------------+
2. Wyznacz programowo najlepszy próg.
- Wpierw wyznacz maksymalną wartość F-measure (przykład kodu poniżej)
- A następnie odpowiadającą jej wartość progu (używając
where … equalTo … select…) - W powyższej tabelce możesz sprawdzić, czy znalezione zostały właściwe wartości (oczywiście one zależą od sposobu podziału na zbiór treningowy i testowy, a więc ziarna
seed)
double maxFMeasure = df_fmeasures.select(functions.max("F-Measure")).head().getDouble(0);
3. Ustaw próg klasyfikatora
lrModel.setThreshold(bestThreshold);
3.3 Ewaluacja na zbiorze testowym
1. Wywołaj funkcję predykcji i skonfiguruj ewaluator
Dataset<Row> predictions = lrModel.transform(df_test); MulticlassClassificationEvaluator eval = new MulticlassClassificationEvaluator() .setLabelCol("Wynik") .setPredictionCol("prediction");
2. Wyznacz:
- accuracy
- weightedPrecision
- weightedRecall
- f1
Oczekiwane są wartości rzędu 0.82-0.83
Nazwy dostępnych metryk:
(f1|accuracy|weightedPrecision|weightedRecall|weightedTruePositiveRate| weightedFalsePositiveRate|weightedFMeasure|truePositiveRateByLabel| falsePositiveRateByLabel|precisionByLabel|recallByLabel|fMeasureByLabel| logLoss|hammingLoss)'
4. LogisticRegressionGrid - tworzenie tabeli ocen
Celem jest utworzenie tabeli ocen postaci, jak poniżej
+--------------+------+----------+--------+--------+ | ImieNazwisko|OcenaC| DataC|OcenaCpp| Wynik| +--------------+------+----------+--------+--------+ |'Xxxxx Yyyyyy'| 3.0|2016-01-17| 2.0|Nie zdał| |'Xxxxx Yyyyyy'| 3.0|2016-01-17| 3.0|Nie zdał| |'Xxxxx Yyyyyy'| 3.0|2016-01-17| 3.5| Zdał| |'Xxxxx Yyyyyy'| 3.0|2016-01-17| 4.0| Zdał| |'Xxxxx Yyyyyy'| 3.0|2016-01-17| 4.5| Zdał| |'Xxxxx Yyyyyy'| 3.0|2016-01-17| 5.0| Zdał| |'Xxxxx Yyyyyy'| 3.5|2016-01-17| 2.0|Nie zdał| |'Xxxxx Yyyyyy'| 3.5|2016-01-17| 3.0|Nie zdał| |'Xxxxx Yyyyyy'| 3.5|2016-01-17| 3.5| Zdał| |'Xxxxx Yyyyyy'| 3.5|2016-01-17| 4.0| Zdał| ...
Uwaga: wynik może się nieco różnić w zależności od konfiguracji, np. progu prawdopodobieństwa
1. Wytrenuj klasyfikator na zbiorze egzamin-cpp.csv. Wykorzystuj kod z poprzedniej części, ustaw próg prawdopodobieństwa.
2. Napisz funkcje
void addClassificationToGrid(SparkSession spark, LogisticRegressionModel lrModel)
która:
- Wczyta zbiór danych
grid.csv - Przetworzy daty, tak aby stały się wartościami numerycznymi
- Skonfiguruje VectorAssembler
- Wywoła funkcję predykcji zmiennej
lrMpdel - Usunie nadmiarowe kolumny
- Za pomocą funkcji
IF()SQL lub zarejestrowanej funkcji użytkownika UDF dokona konwersji etykiet 0→Nie zdał oraz 1→Zdał - Wyświetli wynik
- Zapisze w pliku
grid-with-classification.csv
