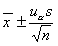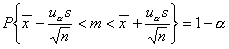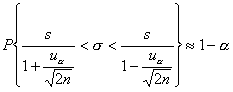W tej części badań zajmiemy się określeniem przedziałów ufności dla dwóch najważniejszych parametrów statystycznych populacji próby, a mianowicie średniej arytmetycznej i odchylenia standardowego. W związku z tym, że zarówno średnia arytmetyczna (), jak i odchylenie standardowe (s) są jedynie estymatorami nieznanych, prawdziwych wartości parametrów statystycznych z populacji generalnej (wartości przeciętnej (m) i odchylenia standardowego (σ)), jesteśmy zmuszeni określić gdzie te prawdziwe wartości się znajdują. W związku z tym, że najczęściej nie jesteśmy w stanie opróbować całej populacji generalnej, nigdy nie będziemy w stanie w sposób punktowy podać, że np. prawdziwa wartość przeciętna wynosi tyle, a tyle. Jesteśmy zatem skazani na podanie przedziału liczbowego, w którym z dowolnie przyjętym przez nas prawdopodobieństwem znajdzie się szukana prawdziwa wartość parametru.
3.2.1 Wyznaczenie przedziału ufności dla średniej
Przy założeniu, że populacja generalna ma rozkład normalny N(m, σ). Przedział ufności dla wartości średniej dany jest wówczas wzorem:
gdzie: - średnia arytmetyczna obliczona na podstawie n - elementowej populacji próby, s - próbkowe oszacowanie odchylenia standardowego, uα wartość zmiennej losowej U o sdandaryzowanym rozkładzie normalnym (N(0, 1)) wyznaczoną w taki sposób aby spełniona była relacja:
Istnieją dwa odrębne sposoby postępowania w przypadku gdy dysponujemy dużą ilością danych i gdy jest ich mniej niż kilkadziesiąt (ok. 30). W związku z tym, że w opracowywanych ćwiczeniach populacje próby wahają się wokół 100 elementów, zajmiemy się tutaj jedynie sposobem postępowania w przypadku licznych zbiorów danych.
W przypadku, gdy mamy do czynienia z liczną populacją próby i rozkład badanej cechy nie podważa zgodności rozkładu cechy w populacji generalnej z rozkładem normalnym (N(m, σ)), obliczamy z próby oszacowania odchylenia standardowego (s). Wtedy przedział ufności dla odchylenia standardowego (σ) w populacji generalnej jest określony wzorem:
gdzie: s - próbkowe oszacowanie odchylenia standardowego, uα wartość zmiennej losowej U o sdandaryzowanym rozkładzie normalnym (N(0, 1)) wyznaczoną w taki sam sposób jak dla średniej arytmetycznej.
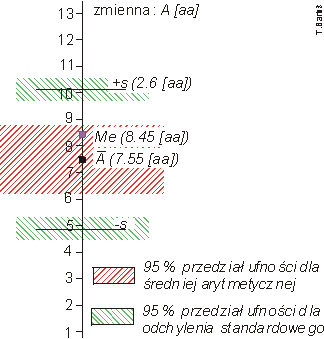
UWAGA: Należy, dla każdej analizowanej zmiennej sporządzić na papierze milimetrowym wykresy przedstawiające: średnią arytmetyczną i medianę obliczoną na podstawie szeregu szczegółowego. Na ten sam wykres należy nanieść odchylenia standardowe. Wykonuje się to przez odłożenie od wartości średniej arytmetycznej wartości: +s oraz -s. Obie odłożone wartości utworzą przedział zmienności próby. Należy go zaznaczyć odpowiednio dobraną szrafurą. Na ten sam wykres należy w końcu nanieść przedział ufności średniej arytmetycznej i przedział ufności odchylenia standardowego. Odkłada się je symetrycznie wokół parametrów, które przybliżają. Przykład wykresu przedstawia Fig. 1. PISMO TECHNICZNE!
Fig. 1. Zmienna losowa X [aa]; 95% przedziały ufności wokół średniej arytmetycznej i odchylenia standardowego
Dostępnych jest 60 zestawów danych. Każdy zestaw składa się z dwóch dokumentów (.doc) oznaczonych odpowiednio w nazwie pliku litermi "A" lub "B" oraz jednym dokumentem .sta (Statistica 5.0) (Sz. cz. A). W pliku: instrukcja_ST_5.doc zamieszczono szczegółową instrukcję do ćwiczeń autorstwa dr inż. Wojciecha Masteja, a w pliku: Sz-srf.xls dane do wykreślenia map.
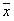 ), jak i odchylenie standardowe (s) są jedynie estymatorami nieznanych, prawdziwych wartości parametrów statystycznych z populacji generalnej (wartości przeciętnej (m) i odchylenia standardowego (σ)), jesteśmy zmuszeni określić gdzie te prawdziwe wartości się znajdują. W związku z tym, że najczęściej nie jesteśmy w stanie opróbować całej populacji generalnej, nigdy nie będziemy w stanie w sposób punktowy podać, że np. prawdziwa wartość przeciętna wynosi tyle, a tyle. Jesteśmy zatem skazani na podanie przedziału liczbowego, w którym z dowolnie przyjętym przez nas prawdopodobieństwem znajdzie się szukana prawdziwa wartość parametru.
), jak i odchylenie standardowe (s) są jedynie estymatorami nieznanych, prawdziwych wartości parametrów statystycznych z populacji generalnej (wartości przeciętnej (m) i odchylenia standardowego (σ)), jesteśmy zmuszeni określić gdzie te prawdziwe wartości się znajdują. W związku z tym, że najczęściej nie jesteśmy w stanie opróbować całej populacji generalnej, nigdy nie będziemy w stanie w sposób punktowy podać, że np. prawdziwa wartość przeciętna wynosi tyle, a tyle. Jesteśmy zatem skazani na podanie przedziału liczbowego, w którym z dowolnie przyjętym przez nas prawdopodobieństwem znajdzie się szukana prawdziwa wartość parametru.