Istnieją dwa rodzaje narzędzi wykorzystywanych w analizach autokorelacji:
Narzędzia globalne testujące obecność ogólnej klasteryzacji (autokorelacji pozytywnej), kiedy obiekty o podobnych wartościach analizowanego atrybutu wystepują w przestrzeni blisko siebie.
Narzędzia służące do identyfikacji lokalnej klasteryzacji (relacje pomiędzy wartościami atrybutów obiektów i wartościami atrybutów ich sąsiadów).
Obie grupy narzędzi bazują na porównaniach różnic pomiędzy obiektami w przestrzeni atrybutowej (jak podobne są obiekty) (macierz Y) z odległością pomiędzy obiektami w przestrzeni geograficznej (niekoniecznie z zastosowaniem odległości euklidesowych) (macierz W).
Macierze wag (W)
Jeżeli macierz Y definiuje zróżnicowanie wartości w przestrzeni atrybutowej, macierz W definiuje odległość pomiędzy obiektami. Odległość niekoniecznie musi być odległością euklidesową (np. obiekty na półwyspach). Macierz W jest generowana na podstawie właściwości geometrycznych obiektów przestrzennych i oceny odległości pomiędzy punktami bądź centroidami obiektów powierzchniowych. Istnieje także możliwość skorzystania z narzędzia "Generate Spatial Weights" w celu utworzenia nieprzestrzennych wag dla odległości bazujących na jakichś wartościach oczekiwanych. Lokalne miary struktury bazują wyłącznie na wartościach macierzy W i Y dla obiektów sąsiadujących.
Rodziaje macierzy wag
Obliczane macierze wag bazują na relacjach przestrzennych obiektów. Konceptualny wybór rodzaju macierzy odległości powinien zawsze odzwierciedlać relacje przestrzenne zachodzące pomiędzy analizowanymi cechami. Im bardziej realistycznie zostaną przedstawione relacje przestrzenne pomiędzy obiektami, tym dokładniejsze będą wyniki.
Relacja odwrotnych odległość lub kwadratu odwrotnych odległości - obiekty położone w bliskim sąsiedztwie mają większy wpływ na obliczenia niż obiekty położone dalej.
Gdy dla parametru Distance Band lub Threshold Distance wprowadzimy wartość "0", wszystkie obiekty będą uważane sąsiadów wszystkich innych obiektów; gdy parametr pozostanie pusty, zostanie zastosowana odległość domyślna.
Wagi dla odległości mniejszych od "1" mogą przy ich odwracaniu powodować niestabilność obliczeń. W związku z tym waga dla obiektów oddalonych o odległośc mniejszą od "1", otrzymują wagę "1".
Fixed distance band każdy obiekt jest analizowany w kontekście obiektów sąsiednich. Obiekty sąsiadujące wewnątrz określonej odległości krytycznej otrzymują wagę "1" i wywierają wpływ na obliczenia dotyczace obiektu docelowego. Obiekty sąsiadujące poza wyznaczoną odległością progową otrzymują wagę "0" i nie są brane pod uwagę w obliczeniach dotyczących obiektu docelowego.
Nearest neighbors najbliższe k obiekty są włączone do analizy. Wymaga określenia numerycznego parametru k.
Contiguity edges only poligonowe obiekty dzielące krawędzie są sąsiadami.
Contiguity edges corners poligonowe obiekty dzielące krawędzie i/lub węzły są sąsiadami.
Delaunay triangulation z centroidów obiektów tworzona jest siatka nienakładajłcych się trójkątów. Obiekty związane z węzłami trójkątów, które dzielą krawędzie są sąsiadami.
Space time window obiekty znajdujące się bliżej od pewnej określonej odległości i w specyficznym interwale czasowym, są sąsiadami.
Obliczenie statystyki globalnej Morana I
Hipoteza zerowa dla narzędzi analitycznych Analyzing Patterns i Mapping Clusters jest następująca:
H0: Rozkład przestrzenny analizowanej cechy jest całkowicie losowy (Complete Spatial Randomness - CSR).
Przed obliczeniem statystyki przestrzennej, należy wybrać przedział ufności czyli prawdopodobieństwo, z którym chcemy poznać prawdziwe położenie parametru statystycznego (te z popuacji generalnej). Prawdopodobieństwo to nazywane jest współczynnikiem ufności. Zaznacza się je najczęściej jako (1-α) i określa jako 100(1-α) - procentowy przedział ufności. Typowe przedziały ufności to 90%, 95% lub 99%. W poszczególnych przypadkach akceptujemy pozostałe 10%, 5% lub 1% błędu jaki możemy popełnić odrzucając prawdziwą hipotezę zerową.
Przeprowadzenie testu na autokorelację przestrzenną wymaga obliczenia wartości statystyki Morana I (Wz. 1).
Wz. 1.
gdzie: Xi - wartość atrybutu obiektu i, Xj - wartość atrybutu obiektu j, N - liczba obiektów, wij - waga połączeń obiektów i i j,
Statystyka globalna Morana I oblicza tendencję zróżnicowania obiektu i i sąsiadującego z nim obiektu j od średniego zróżnicowania w zbiorze danych. W celu kompensacji nierównych liczb sąsiadów, powszechnie stosuje się opcję normalizacji rzędami. Macierz Y jest mnożona przez macierz wag W. Wynik jest miarą globalnego poziomu autokorelacji.
W praktyce, weryfikacji hipotezy zerowej dokonuje się w oparciu o ocenę zwracanych przez narzędzia analizy strukturalnej dwóch wartości: Z-score i p.
Z-score to w istocie zestandaryzowana wartość statystyki Morana I (Wz. 2). Obliczona statystyka z_score ma dla dużych liczebności populacji próby rozkład Normalny N(0, 1). Wyliczona wartość pokazuje jak bardzo odbiega od oczekiwanej wartości przeciętnej. Jest więc krotnością odchylenia standardowego. Jeżli np. narzędzie zwraca wynik z-score = +2,5, można powiedzieć, że wynik odbiega od oczekiwanej wartości przeciętnej o 2,5 odchylenia standardowego.
Wz. 2.
gdzie: x = I μ = E(I) wartość oczekiwana I σ2 = Var(I) odchylenie standardowe rozkładu zmiennej losowej I szczegółowe wzory
p jest prawdopodobieństwem popełnienia błędu pierwszego rodzaju tzn. błędu polegającego na odrzuceniu hipotezy zerowej, która w rzeczywistości nie jest fałszywa. Gdy wartość p jest bardzo mała, oznacza to, że jest bardzo mało prawdopodobne, że obserwowana struktura przestrzenna jest dziełem procesów losowych. W takich przypadkach należy hipotezę zerową odrzucić.
Odrzucenie (bądź przyjęcie) hipotezy zerowej odbywa się na skutek weryfikacji położenia wyliczonej wartości statystyki z-score (lub p) względem obszaru krytycznego rozkładu gęstości prawdopodobieństwa zmiennej losowej z_score (N(0, 1)).
Na Fig. 1., za pomocą kolorów zaznaczono obszary krytyczne dla różnych poziomów istotności (0.1; 0.05; 001). Jeżeli uzyskana realizacja statystyki testowej z_score wpada do obszaru krytycznego, hipoteza zerowa zostaje odrzucona, jeżeli zaś uzyskana realizacja statystyki testowej nie wpada do obszaru krytycznego - nie ma podstaw do odrzucenia H0.
Bardzo wysokie lub bardzo niskie (ujemne) wartości z-score są powiązane z bardzo małymi wartościami p. Jeżeli w wyniku przeprowadzonej analizy struktury otrzymujemy małe wartości p i/lub bardzo wysokie lub bardzo niskie wyniki z_score, oznacza to, że jest mało prawdopodobne, że obserwowana struktura przestrzenna odzwierciedla strukturę losową reprezentowaną przez hipotezę zerową.
Jeżeli p <=α: H0 odrzucamy
Jeżeli p > α: nie ma podstaw aby odrzucić H0
Odrzucenie hipotezy zerowej oznacza, że zamiast struktury losowej, obiekty (lub związane z nimi wartości) wykazują istotną statystycznie klastrowość (lub dyspersję). Gdy w krajobrazie (lub w danych przestrzennych) zauważymy klastrową strukturę przestrzenną mamy dowód na zaistnie w tym miejscu jakichś procesów przestrzennych.
Poszukiwanie właściwej odległości sąsiedztwa (Incremental Spatial Autocorelation)
Narzędzie Incremental Spatial Autocorelation wykorzystuje globalny wskaźnik autokorelacji Morana I do przeprowadzenia serii obliczeń bazujących na wzrastającej odległości sąsiedztwa. Dla każdej odległości badany jest poziom klasteryzacji struktury przestrzennej. Poziom klasteryzacji determinuje zwracana wartość z_score. Typowo, wraz ze wzrostem odległości rośnie wartość z_score wskazując na intensyfikację klasteryzacji. W szczególnych odległościach występują charakterystyczne piki z_score.
Jak wysokie/niskie klastrowanie (Getis-Ord General G)
Alternatywą dla globalnej statystyki Morana jest ststystyka Getis-Ord. Generalna statystyka G używa tych samych macierzy Y i W ale test jest nieco inny. Wyniki generalnej statystyki Getis-Ord są w stanie wskazać, czy istnieją klastry wysokich lub niskich wartości.
Klastry lokalne
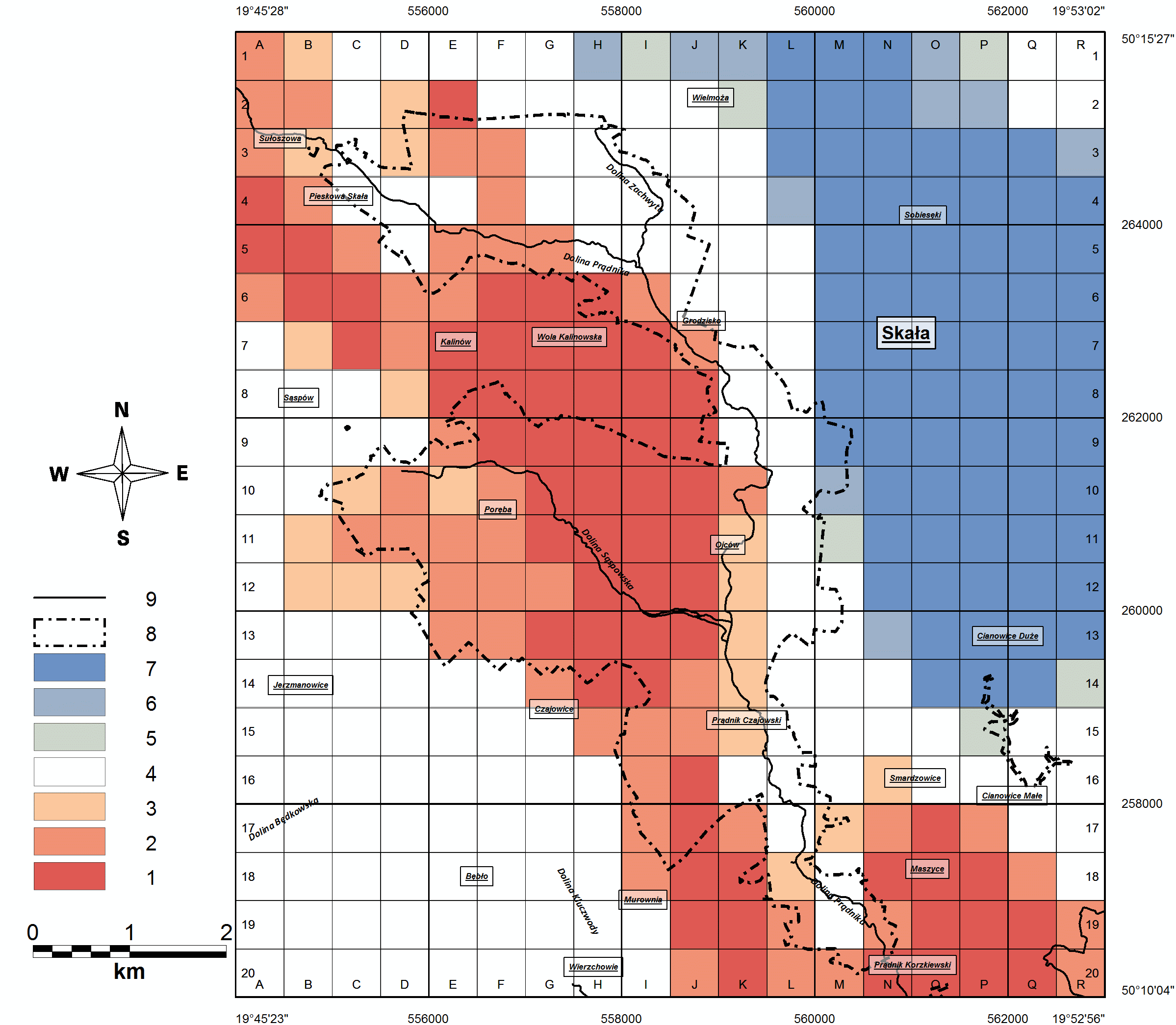
Istnieją 2 narzędzia służące do badania autokorelacji lokalnej Dla przypomnienia, ich algorytm opiera się na tych samych macierzach W i var>Y ale wyłącznie dla obiektów bezpośrednio sąsiadujących ze sobą. Pierwszym narzędziem jest "Getis-Ord GI*" (High/Low Clustering) (Fig. 2), a drugim Cluster and Outlier Analysis (Anselin Local Morans I) (Fig. 3). Aparat matematyczny obu narzędzi jest ten sam jak dla globalnego wariantu analizy klasteryzacji, ale wyniki są odmienne. Statystyka Getis-Ord GI* potrafi z różnymi poziomami istotności zidentyfikować "hot spot" (klastry wysokich poziomach atrybutu) lub "cold spot" (klastry o niskich wartościach atrybutu).
PRZYKŁAD
Fig. 2. Klastry o wysokim i niskim poziomie georóżnorodności względnej rejonu OPN. Pola tworzące klaster o wysokim poziomie georóżnorodności: 1 - na poz. istotności 0,01; 2 - na poz. istotności 0,05; 3 - na poz. istotności 0,1; 4 - pola nieistotne statystycznie; pola tworzące klaster o niskim poziomie georóżnorodności: 5 - na poz. istotności 0,1; 6 - na poz. istotności 0,05; 7 - na poz. istotności 0,01; 8 - granice OPN; 9 - cieki powierzchniowe
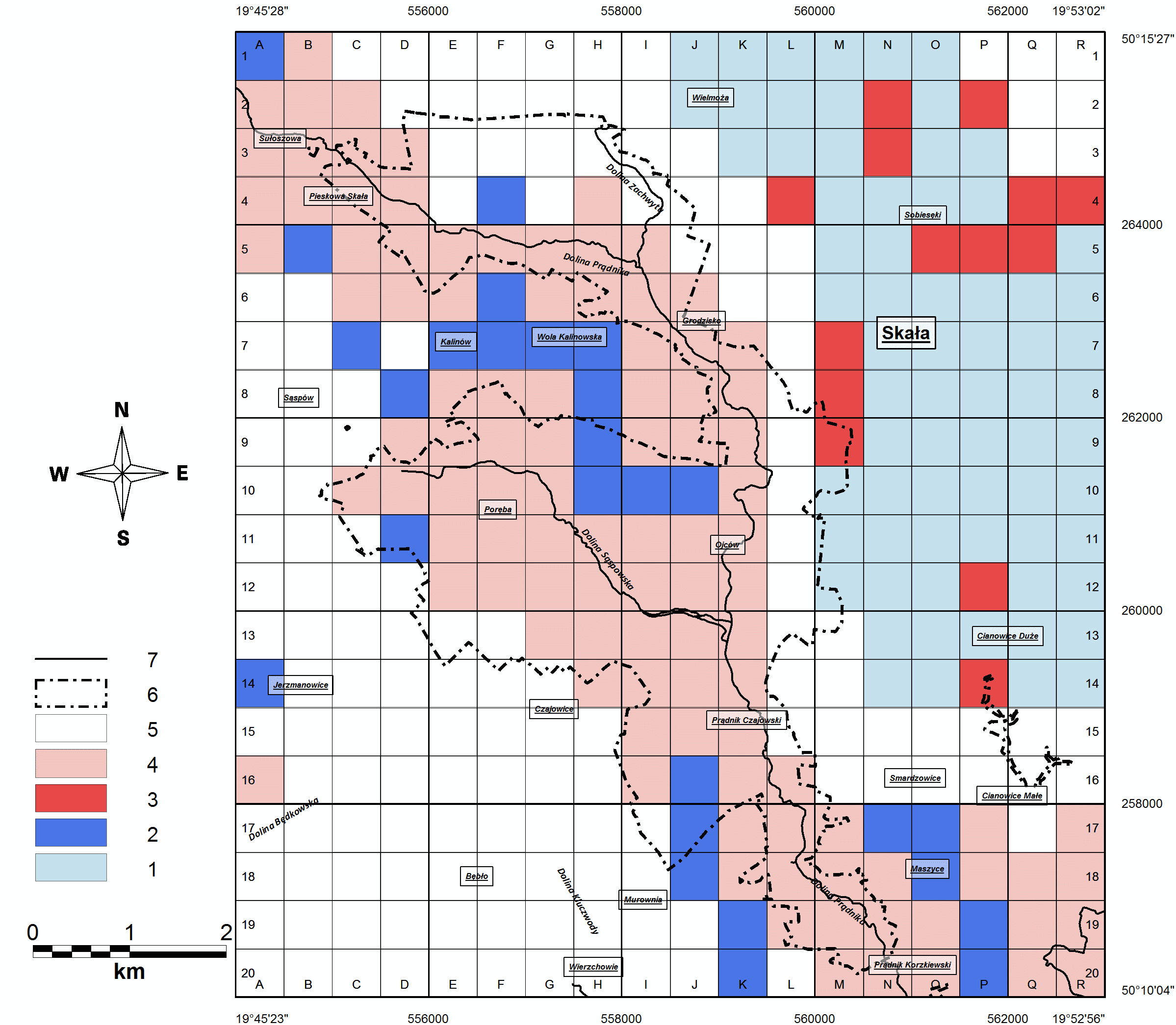
W celu wykrycia lokalnych anomalii występujących wewnątrz klastrów o wysokich i niskich wartościach badanego parametru, stosowana jest analiza LISA. Umożliwia ona określenie podobieństwa każdego obiektu przestrzennego względem swoich lokalnych sąsiadów. Do obliczeń wykorzystywana jest lokalna statystyka Morana I (Anselin 1995). Jej zastosowanie pozwola na poziomie istotności 0,05; na określenie położenia:
obiekty o wysokich wartościach atrybutu otoczone obiektami o wysokich wartościach artybutu,
obiekty o niskich wartościach atrybutu otoczone obiektami o niskich wartościach artybutu,
obiekty o wysokich wartościach atrybutu otoczone obiektami o niskich wartościach artybutu,
obiekty o niskich wartościach atrybutu otoczone obiektami o wysokich wartościach artybutu.
PRZYKŁAD
Fig. 3. Zróżnicowanie georóżnorodności bezwzględnej rejonu Ojcowskiego Parku Narodowego (statystyka Anselin Local Morans I, próg sąsiedztwa: 2000m). 1 - pola o niskiej georóżnorodności otoczone polami o niskim poz. parametru; 2 - pola o niskim poz. georóżnorodności otoczone przez pola o wysokim poz. parametru; 3 - pola o wysokim poz. georóżnorodności otoczone przez pola o niskim poz. parametru; 4 - pola o wysokim poz. georóżnorodności otoczone przez pola o wysokim poz. parametru; 5 - pola statystycznie nieistotne; 6 - granice OPN; 7 - cieki powierzchniowe
Wykorzystane materiały
Anselin, L., 1995. Local Indicators of Spatial Association - LISA, Geographical Analysis, 27(2), 93-115.
Getis A., Ord J.K., 1992. The analysis of spatial association by distance statistics. Geographical Analysis, 24(3), 189-206.
Holmes E., 2015. Hot Spot analysis using Moran's I and getis-ord statistics in ArcMap/ArcGIS.

 Wz. 1.
Wz. 1.
 Wz. 2.
Wz. 2.